HA&ZooKeeper
本文最后更新于:2021年6月14日 晚上
HA&ZooKeeper
zookeeper
zk概述
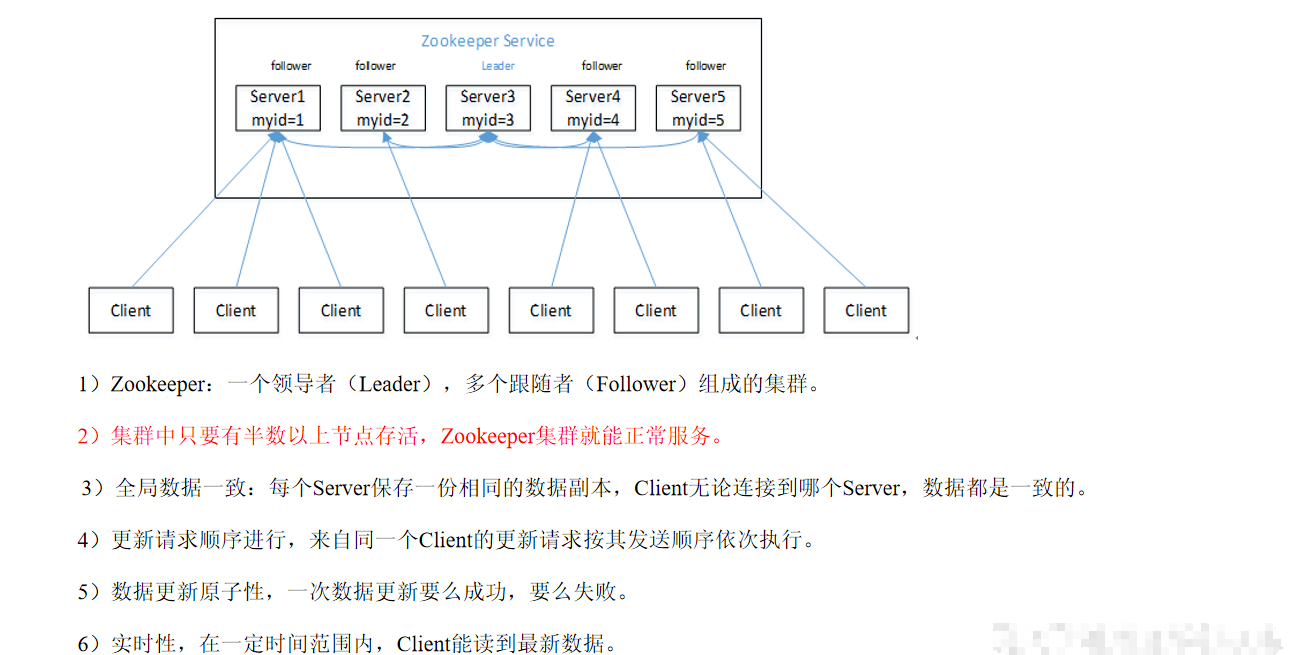
- ZooKeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
- 设计模式:是一个基于观察者模式设计的分布式服务管理框架,它辅助存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
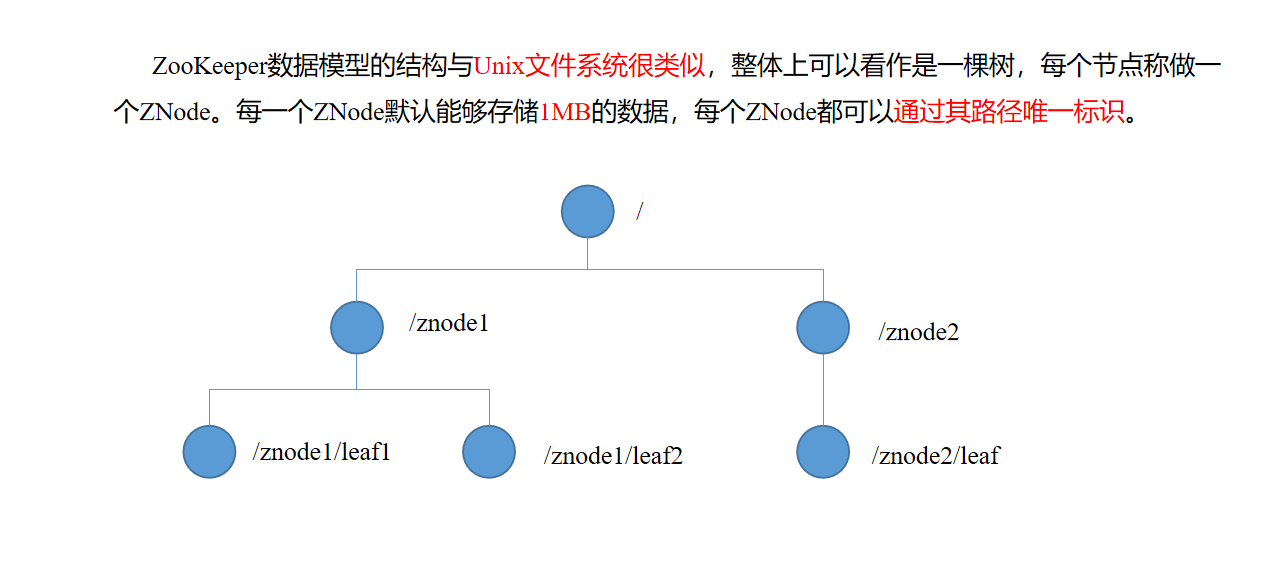
- Zookeeper特点,数据结构
zk实战应用
客户端命令
启动客户端:zkCli.sh
命令基本语法 功能描述 help 显示所有操作命令 ls path [watch] 使用 ls 命令来查看当前znode中所包含的内容 ls2 path [watch] 查看当前节点数据并能看到更新次数等数据 create 普通创建-s 含有序列-e 临时(重启或者超时消失) get path [watch] 获得节点的值 set 设置节点的具体值 stat 查看节点状态 delete 删除节点 rmr 递归删除节点
zk内部原理
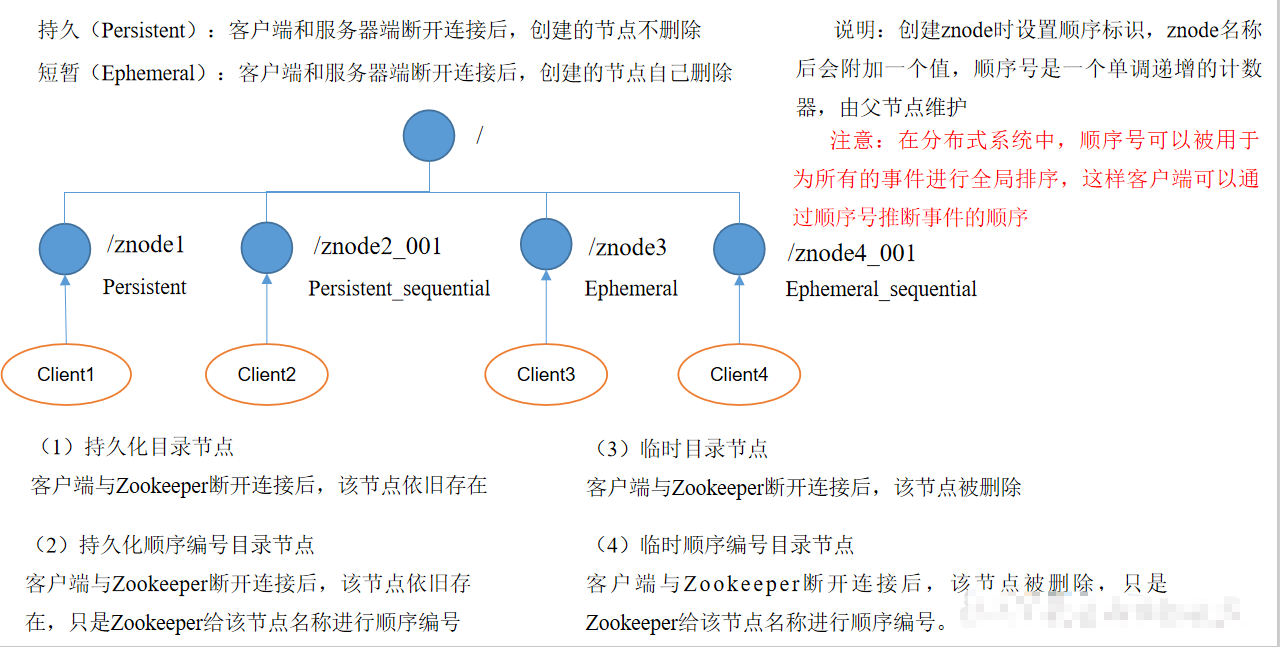
节点类型
Stat结构体
czxid-创建节点的事务zxid
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
监听器原理

选举机制
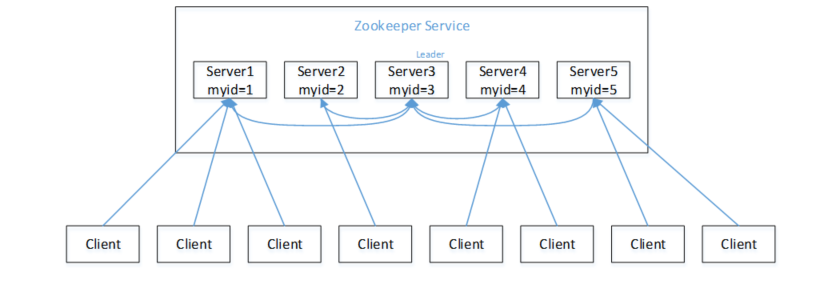
- 集群会通过比较先会比较zxid,若zxid相同则比较myid选择leader(每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID)
- 若第一次启动集群(zxid相等)myid如图所示:则大致流程如下:
- server1投票给自己,但是票数没到集群机器的半数以上,选举无法进行。server1状态为LOOKING
- server2启动,发起选举,投票给自己,1发现2的myid大,更改选票为2。同理选举依然没法完成。
- 3启动,发起选举,投给自己,1,2发现3的myid大。则1,2将选票投给3,3获得三票。成为Leader,1,2更改状态为FOLLOWING。3更改状态为LEADING。
- 4启动,发起选举,1,2,3不在是LOOKING状态,不会更改选票信息。交换选票信息后,3为3票,4为一票,少数服从多数,更改选票信息为server3,更改状态为FOLLOWING。
- 同4一样
ZAB
ZAB协议是专门为zookeeper实现分布式协调功能而设计。zookeeper主要是根据ZAB协议是实现分布式系统数据一致性
写数据流程:
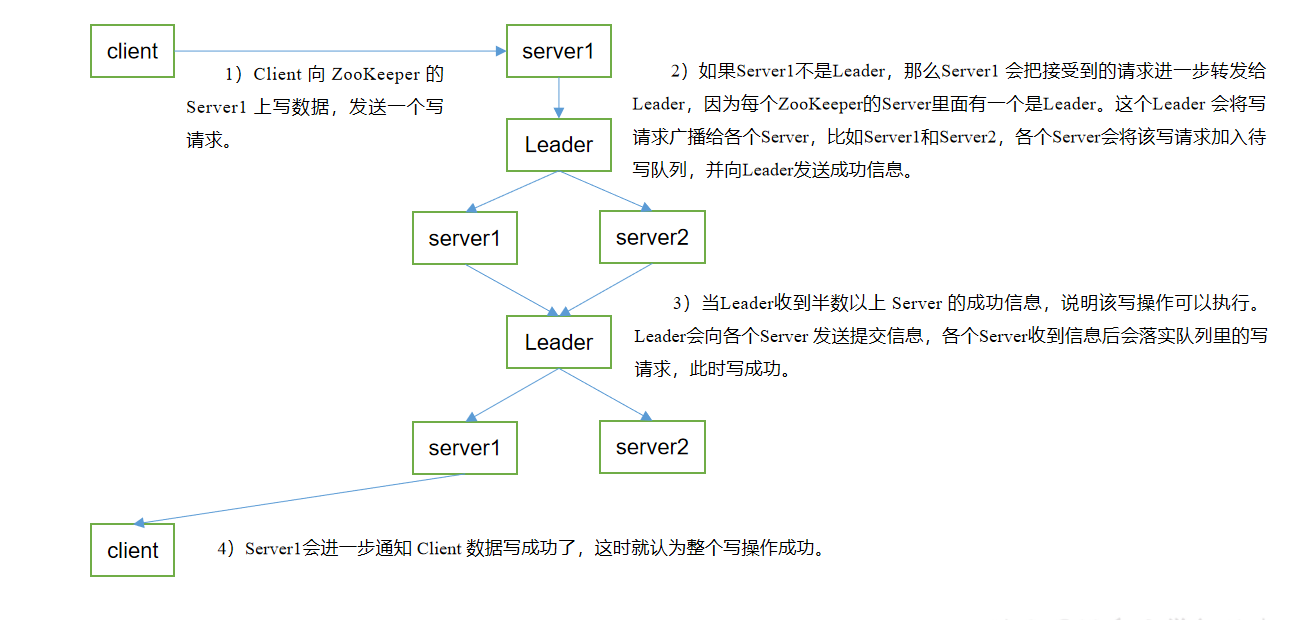
- 三个服务器会对是否写数据提出意见,都同意那正常执行写操作
- 一个server不同意而总票数支持同意,该server自杀再重启,再朝Leader同步信息
- leader不同意,但总票数同意。leader自杀重启,重新选举leader,重启后再向leader同步数据
- 为什么会不同意:查看zxid,如果发来的zxid事物请求比自身的大才会同意
- 总之就是要尽可能的保持集群数据的一致性。
HA
HA概述
- HA(High Availablity)
- 实现高可用最重要的是消除单点故障
- 防止出现namenode节点挂了,无法正常提供服务
HA工作机制
故障转移机制 HDFS-HA
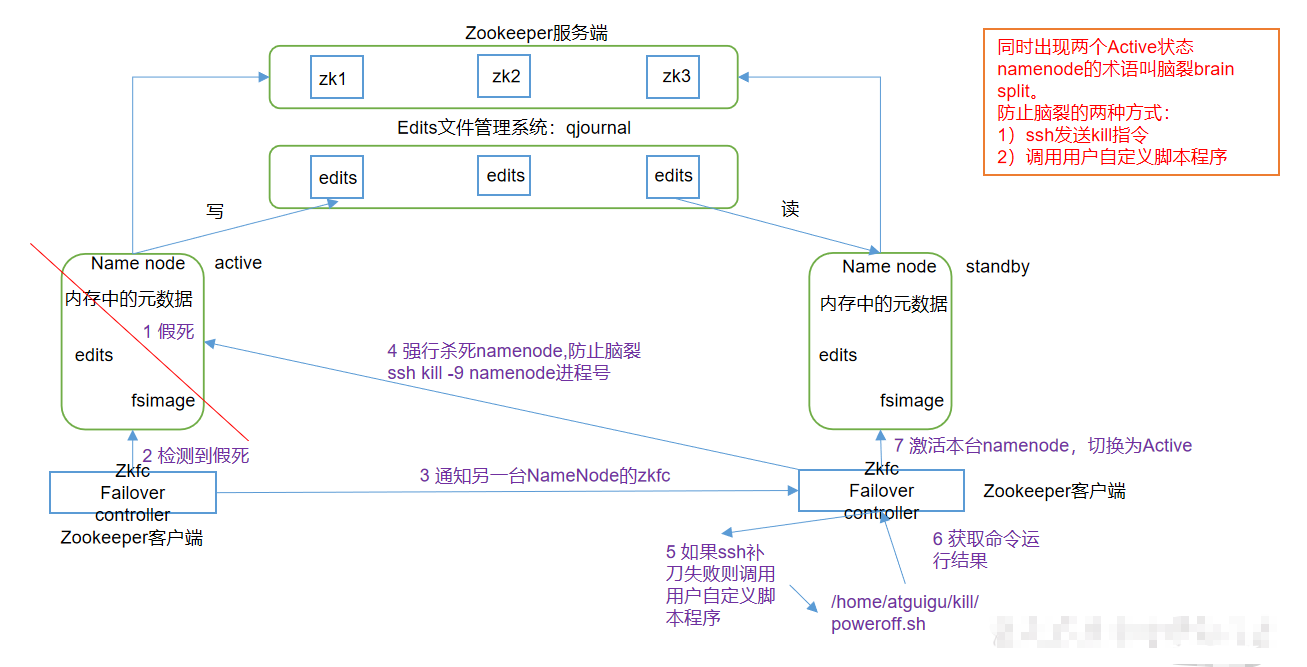
故障转移机制
- 为了保证数据不丢失,一个失效后另一个补上不会丢失数据,日志文件写到第三方平台(相当于2nn)
- 新激活的namenode 可以从第三方,读取edits文件将缺少的数据补上,防止数据丢失
- Zkfc检测到假死后是通过zookeeper服务器将信息传到其它的namenode的zkfc
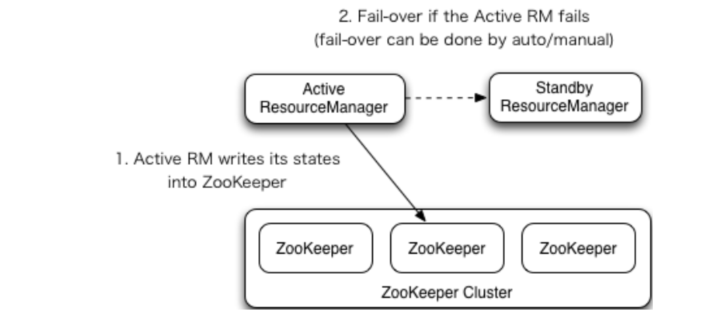
YARN-HA
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!