project_logcollect
本文最后更新于:2023年11月16日 下午
电商采集项目搭建流程
自动生成数据脚本
- 生成用于测试的数据
数据采集模块
Hadoop安装
在这里只说以下大致步骤以及容易出错的地方
配置集群之间分发数据的脚本,以及集群之间ssh免密登录
hadoop安装,解压就行,注意解压的目录。
核心文件配置:
- core-site.xml文件配置
- hdfs-site.xml文件配置,因为是测试,在这里设置HDFS副本数量为1,防止存储不够,浪费存储。
- yran-site.xml文件配置
- mapred-site.xml文件
- workers文件配置,注意不用多打空格等输入错误,里面配置hadoop的datanode节点的主机名。
第一次启动注意要先格式化namenode。bin/hdfs namenode -format
常见web客户端:
- hadoop100:9870。HDFS的Web界面
- yarn的web界面:hadoop101:8088
- 历史服务器hadoop102:19888
单点启动关闭命令
1
2
3
4
5
6#HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
#Yarn
yarn --daemon start/stop resourcemanager/nodemanager
#历史服务器
mapred --daemon start historyserver配置历史服务器
配置日志的聚集
集群时间同步
配置一下压缩
可以测试一下集群基础性能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
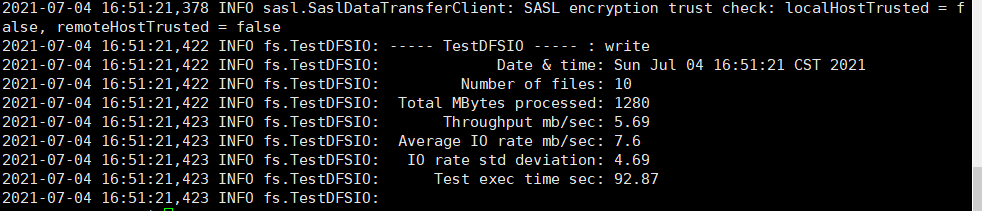
读写性能测试
#读取HDFS集群的10个128M文件
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
#删除测试数据
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
运算速度测试
#使用RandomWriter来产生随机数,每个节点运行10个Map任务,每个Map产生大约1G大小的二进制随机数
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar randomwriter random-data
#执行排序程序
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar sort random-data sorted-data
#验证数据是否排序成功
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-data
ZooKeeper安装
在/zookeeper-3.5.7/这个目录下创建zkData
在/zookeeper-3.5.7/zkData目录下创建一个myid的文件,myid唯一。
重命名/zookeeper-3.5.7/conf这个目录下的zoo_sample.cfg为zoo.cfg
修改数据存储路径:dataDir=/opt/module/zookeeper-3.5.7/zkData
cluster下增加集群配置
Kafka
Kafka遇到的坑:– Error while fetching metadata with correlation id : {LEADER_NOT_AVAILABLE}
原因:无法识别Kafka hostname
解决:修改kafka/config/server.properties配置
配置llisteners=PLAINTEXT://hadoop100:9092
配置advertised.listeners=PLAINTEXT://hadoop100:9092
Kafka压力测试
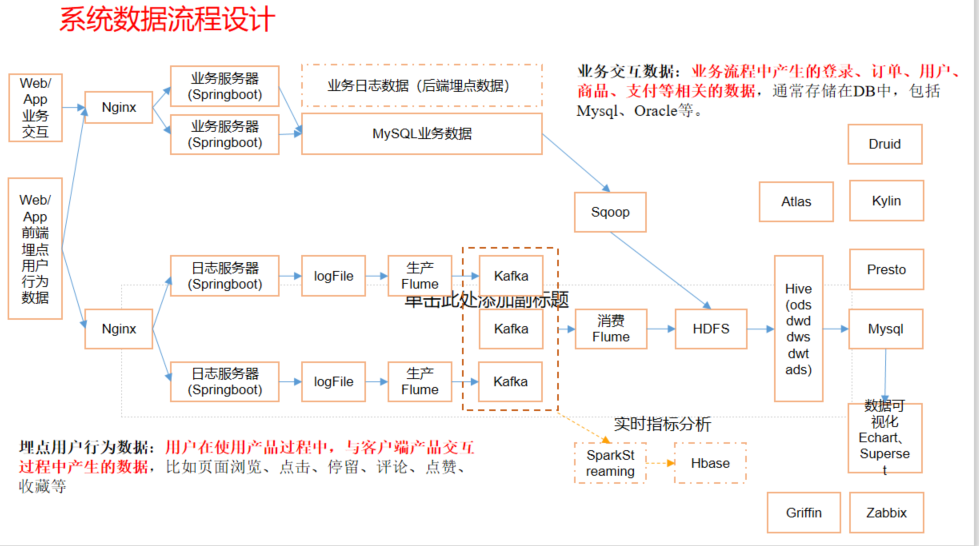
项目基础架构
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!