Spark
本文最后更新于:2024年9月12日 晚上
Spark
Spark入门
spark是一种基于内存的快速,通用,可扩展的大数据分析计算引擎。
spark内置模块

- spark core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
- Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
- Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
- Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
- Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
- 集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。
Spark运行模式
运行模式:单机模式,集群模式
- Local模式:本地部署单个spark模式
- Standalone:spark自带的任务调度模式
- YARN模式:spark使用Hadoop的YARN组件进行资源与任务调度。(重点)
- 修改/opt/module/spark/conf/spark-env.sh,添加YARN_CONF_DIR配置:YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop,保证后续运行任务的路径都变成集群路径
- Mesos模式:saprk使用Mesos平台进行资源与任务的调度。
运行流程
- Spark有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
- yarn-client:Driver程序运行在客户端,适用于交互,调试,希望立即看到app的输出。
- yarn-cluster:Driver程序运行在由ResourceManager启动的APPMaster,适用于生产环境。
端口号总结
- spark历史服务器端口号:18080 hadoop历史服务器端口号:19888
- spark Master web服务器端口号:8080 Hadoop的namenode web端口号:9870
- spark Master内部通信服务端口号:7077 Hadoop的namenode内部通信服务端口号:8020
- Spark查看当前Spark-shell运行任务情况端口号:4040
- hadoop yarn任务运行情况查看端口号:8088
SparkCore
RDD概述
RDD(Resilient Distributed Dataset)弹性分布式数据集,是Spark中最基本的数据抽象。
RDD特性
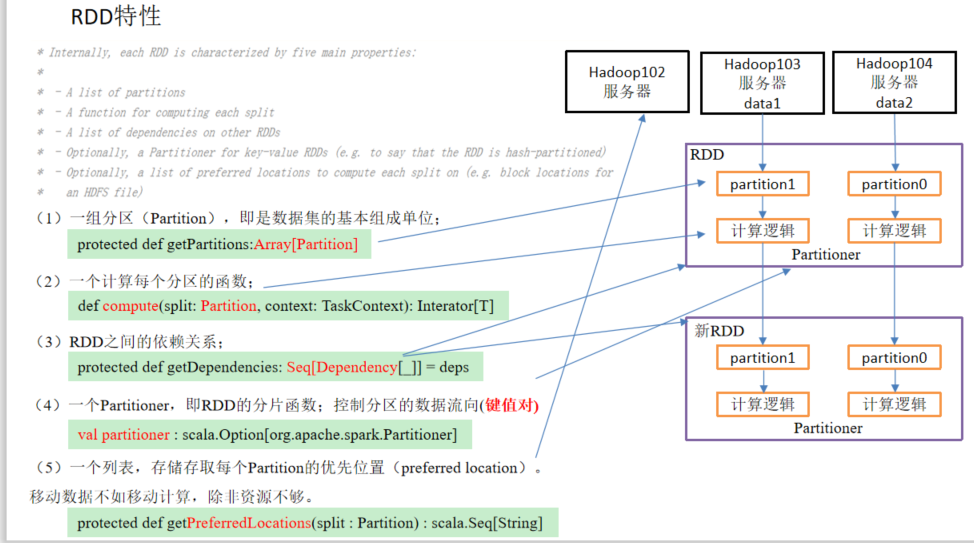
yarn模式下的sparkWordCount实现案例:大致流程
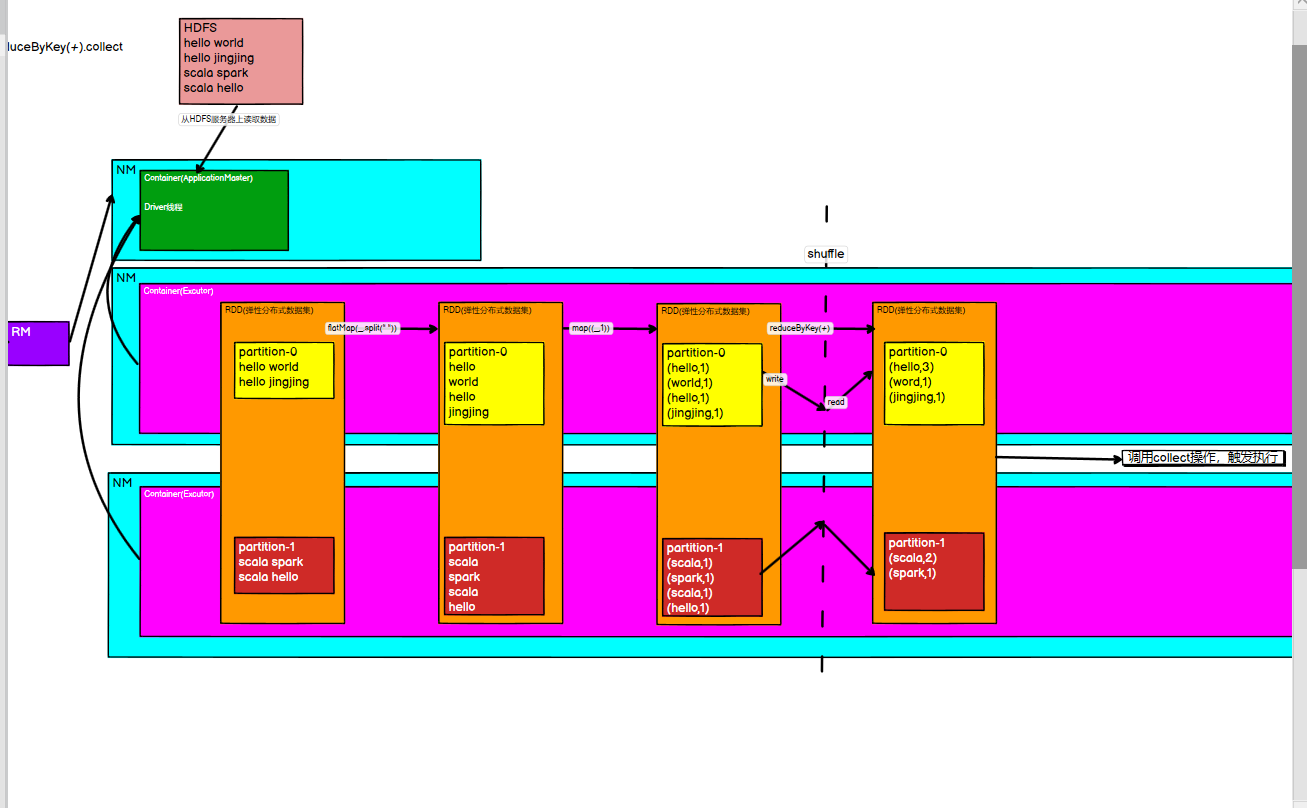
- 任务从客户端发送到ReourceManager,RM指定一个NM创建一个AppMster进程,创建spark的一个Driver线程,Driver线程将任务分配到其它的NM,其它的NodeManager申请container,container会创建spark的一个excutor线程,RDD会根据分区进行一系列transformations转换定义,也会在一些情况下有shuffer过程,程序不会立刻执行,而是直到调用action触发调用RDD的计算。

RDD编程
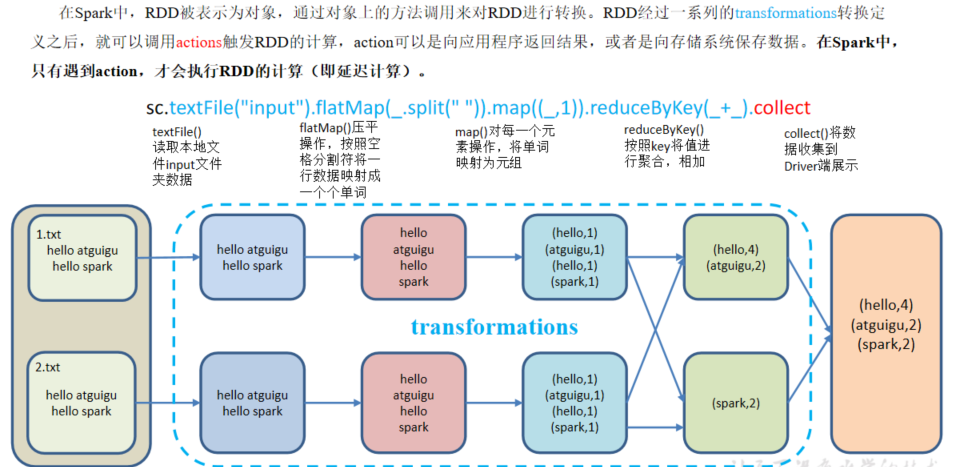
- 在spark中只有遇到action(如rdd.collect)才会执行RDD的计算(即延迟计算)
RDD的创建
- 从集合中创建
- 从外部存储(HDFS,Hbase)创建
- 通过RDD的转换算子转换
分区规则
分区数:
创建RDD的方法都可以指定分区数
如果SparkConf.setMaster(local[*]),从集合创建默认是cpu核数,从外部存储创建默认是math.min(分配给应用的CPU核数,2)
数据分区规则:
- 通过集合创建RDD的情况:
1
2
3
4
5
6
7
8def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
//通过返回这样一个左闭右开的迭代元组对象,元组里面是以一组组下标,根据下标划分集合元素通过外部存储创建RDD的情况:
- 默认分区规则math.min(分配给应用的CPU核数,2)
- 指定分区:在TextFile方法中,第二个参数minPartitions,表示最小分区数(是最小,不代表实际的分区数)
- 在实际计算分区个数时,会根据文件的总大小和最小分区数进行相除运算,如果余数为0,那最小分区数就是实际分区数,否则需要进一步计算得到分区数。
- 切片规划:调用FileInputFormat中的getSplits方法
- 注意:getSplits文件返回的是切片规划,真正读取是在compute方法中创建LineRecordReader读取的,有两个关键变量start=split.getStart() end = start + split.getLength
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
FileStatus[] files = listStatus(job);
// 输入的文件数量
// Save the number of input files for metrics/loadgen
job.setLong(NUM_INPUT_FILES, files.length);
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
FileSystem fs = path.getFileSystem(job);
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[] splitHosts = getSplitHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
String[] splitHosts = getSplitHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts));
}
} else {
String[] splitHosts = getSplitHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
LOG.debug("Total # of splits: " + splits.size());
return splits.toArray(new FileSplit[splits.size()]);
}
Transformation转换算子(重点)
- 算子:从认知心理学角度来讲,解决问题其实是将问题的初始状态,通过一系列的转换操作(operator),变成解决状态。
- 转换算子(Transformation)执行完毕之后,会创建新的RDD,并不会马上执行计算。
- 行动算子(Action)执行后,才会触发计算。
Value类型
map
- 对RDD中的元素进行一个个映射
- 新RDD中的每一个元素都是原来RDD中每一个元素依次应用f函数而得到的。
mapPartitions
- 以分区为单位,对RDD中的元素进行映射
mapPartitionsWithIndex
- 以分区为单位,对RDD中的元素进行映射,并且带分区编号
flatMap
- 对RDD中的元素进行扁平化处理
- 在flatMap操作中,f函数的返回值是一个集合,并且会将每一个该集合的元素拆分出来放到新的RDD中。
glom
- 将RDD中每一个分区中的单个元素,转换为数组
groupBy
- 按照一定的规则,对RDD中的元素进行分组
- 按照传入函数的返回值进行分组,将相同的key对应的值放入一个迭代器
filter
- 按照一定的规则,对RDD中的元素进行过滤
sample
对RDD中的元素进行抽样
参数一:是否抽象放回 true放回,false不放回
参数二 :参数一以为true时,放回抽样,参数二代表期望元素出现的次数 参数大于0
参数二:参数一为false时,不放回抽样,参数二代表每一个元素出现的概率[0,1]
参数三:随机算法的初始种子
takeSample(行动算子)
distinct
- 去重
- 底层是通过map+reduceByKey完成去重操作
改变分区
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null) : RDD[T]coalesce 一般用于缩减分区,默认不执行shuffle
reparation 一般用于扩大分区,默认执行shuffle,底层调用的就是coalesce
sortBy
- 按照指定规则,对RDD中的元素进行排序,默认升序
- 该操作用于排序数据,在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为正排序。排序后新产生的RDD分区数与原RDD的分区数一致。
pipe()
- 对于RDD中的每一个分区,都会执行pipe 算子中指定的脚本
双Value类型
- 两个RDD之间进行操作:对源RDD和参数RDD进行操作,返回一个新的RDD
- union()
- 并集
- intersection
- 交集
- subtract
- 差集
- zip
- 拉链,该操作可以将两个RDD中的元素,以键值对的形式进行合并。其中,键值对中的key为第一个RDD中的元素,value为第二个RDD中的元素。
- 注意必须要保证分区数以及每一个分区中元素的个数一致
Key-Value类型
PartitionBy
- 按照指定的分区其,通过key对RDD中的元素进行分区
- 默认分区器 HashPartitioner
reduceByKey
- 将相同的key放在一起,对value进行聚合操作
groupByKey
- 按照key对RDD中的元素进行分组。对每个key进行操作,但只生成一个seq ,并不进行聚合。
reduceByKey和groupByKey的区别
- reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]
- groupByKey: 按照key进行分组,直接进行shuffle
- 在不影响业务逻辑的前提下,优先选用reduceByKey。求和操作不影响业务逻辑,求平均值影响业务逻辑。
aggregateByKey[(zeroValue)(分区内计算规则,分区间计算规则)]
- (1)zeroValue(初始值):给每一个分区中的每一种key一个初始值;
(2)seqOp(分区内):函数用于在每一个分区中用初始值逐步迭代value;
(3)combOp(分区间):函数用于合并每个分区中的结果。
- (1)zeroValue(初始值):给每一个分区中的每一种key一个初始值;
foldByKey(zeroValue)(分区间计算规则)
- 是aggregateBykey的简化,分区内和分区间计算规则相同
combineByKey (对当前key的value进行转换,分区内计算规则,分区间计算规则)
几种聚合算子对比
上面四个聚合算子底层都是调用
1
2
3
4
5
6
7
8
9
10
11>reduceByKey(_+_)
combineByKeyWithClassTag[V]((v: V) => v, func, func)
>aggregateByKey(zeroValue)(cleanedSeqOp,combOp)
combineByKeyWithClassTag[U]((v: V) => cleanedSeqOp(createZero(), v),cleanedSeqOp, combOp)
>foldByKey
combineByKeyWithClassTag[V]((v: V) => cleanedFunc(createZero(), v),cleanedFunc, cleanedFunc)
>combineByKey
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners)
sortByKey
- 按照RDD的中的key对元素进行排序
mapValues
- 只对RDD中的value进行操作
join&cogroup
- 连接操作
行动算子(Action)
行动算子执行后,才会触发计算
reduce
- 对RDD中的元素进行聚合
collect.foreach和foreach
collect.foreach:将每一个Excutor中的数据收集到Driver,形成一个新的数组
.foreach不是一个算子,是集合的方法,是对数组中的元素进行遍历foreach:对RDD中的元素进行遍历
count
- 获取RDD中元素的个数
countByKey
- 获取RDD中每个key对应的元素个数
first
- 获取RDD中的第一个元素
take
- 获取RDD中的前几个元素
takeOrdered
- 获取排序后的RDD中的前几个元素
aggregate&fold
- aggregateByKey 处理kv类型的RDD,并且在进行分区间聚合的时候,初始值不参与运算
- fold 是aggregate的简化版
save相关的算子
- saveAsTextFile
- saveAsObjectFile
- saveAsSequenceFile(只针对KV类型RDD)
RDD序列化
- 为什么要序列化:因为在spark程序中,算子相关的操作在Excutor上执行,算子之外的代码在Driver端执行,在执行有些算子时,需要使用Driver里面定义的数据,这就涉及到了跨进程或者跨节点之间的通讯,所以这就涉及到了跨进程或者跨节点之间的通讯。所以要求传递给Excutor中的数组所属的类型必须实现Serializable接口。
- 如何判断是否实现了序列化接口:在作业job提交之前,其中有一行代码 val cleanF = sc.clean(f),用于进行闭包检查之所以叫闭包检查,是因为在当前函数的内部访问了外部函数的变量,属于闭包的形式。如果算子的参数是函数的形式,都会存在这种情况。
RDD的血缘关系以及依赖关系
- 血缘关系
- toDebugString
- 依赖关系
- dependencies
- 窄依赖:父RDD一个分区中的数据,还是交给子RDD的一个分区处理
- 宽依赖:父RDD一个分区中的数据,交给子RDD的多个分区处理。分区中数据打乱了,进行了shuffle操作
Spark的Job调度(重点)
- 集群(Standalone|Yarn)
- 一个Spark集群可以同时运行多个spark应用
- 应用(Application)
- 我们所编写完成某些功能的程序
- 一个应用可以并发的运行多个Job
- Job
- Job对应着应用中的行动算子,每次执行一个行动算子,都会提交一个Job
- 一个Job由多个stage组成
- Stage
- 一个宽依赖做一次阶段的划分
- 阶段的个数=宽依赖的个数+1
- 一个Stage由多个Task组成
- Task
- 每一个阶段最后一个RDD的分区数,就是当前阶段的Task个数
数据读取与保存
RDD的持久化
- cache 底层调用persist,默认存储在内存中 相当于缓存,当有多个行动算子时,前面相同的操作部分可以进行缓存,减少重复计算。
- persist 可以通过参数指定存储级别 内存,磁盘
- checkpoint 检查点会切断血缘关系,会把中间结果记录下来,一般存储在高可用的存储系统中(如HDFS)
- 作用:为了避免容错执行时间过长
- 一般和缓存搭配使用,因为在切断血缘关系后,为保证中间结果的正确性,会将前面的操作再运行一遍,加上缓存后,就不用再重复计算一遍。
文件保存
- textFile
- sequenceFile SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)
- objectFile 对象文件是将对象序列化后保存的文件,采用Java的序列化机制。
- Json 本质还是通过textFile读取文本,对读到的内容进行处理
- HDFS
- MySQL
- map———mapPartition
- foreach——-foreachPartion
累加器 广播变量
- Spark三大结构
- RDD 弹性分布式数据集
- 累加器 分布式共享只写变量
- 广播变量 分布式共享只读变量
- 累加器 Driver端的变量会复制到Excutor端的Task中去,但是Driver端不能读到Excutor中的变量。累加器可以实现将EXcutor端数据的改变传回到Driver端去
- 自定义累加器:继承AccumulatorV2,设定输入、输出泛型 重写方法
- 广播变量
- 在多个并行操作中(Executor)使用同一个变量,Spark默认会为每个任务(Task)分别发送,这样如果共享比较大的对象,会占用很大工作节点的内存。
- 广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Task操作使用。
- 实现Excutor端Task之间共享变量,节省内存
Spark SQL
Spark SQL概述
Spark SQL是Spark用于结构化数据(structured data)处理Spark模块
与Hive类似,将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快
Spark Sql提供了2个编程抽象,类似Spark Core中的RDD
- DataFrame
- DataSet
DataFrame
- 在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据中的二维表格。
- DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
- 这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
DataSet
- DataSet是分布式数据集合。
- 是DataFrame的一个扩展。它提供了RDD的优势(强类型,使用强大的lambda函数的能力)以及Spark SQL优化执行引擎的优点。DataSet也可以使用功能性的转换(操作map,flatMap,filter等等)。
- DataFrame是DataSet的特例
Hive on Spark 和Spark on Hive
- hive on spark
- 就是把hive查询从MR换成spark,参考官方的版本配置,不然很容易遇到依赖冲突。
- 之后还是在hive上写hivesql,但是执行引擎是spark,任务会转化成spark rdd算子去执行。
- 优化器还是hive的优化器,而没有spark sql自带的优化器的效果好
- spark on hive
- 就是同步Sparksql,加载hive的配置文件,获取到hive的元数据信息
- Spark sql获取到hive的元数据信息之后就可以拿到hive的所有表的数据
- 接下来就可以通过spark sql来操作hive表中的数据
- spark beeline
- Spark Thrift Server 是 Spark 社区基于 HiveServer2 实现的一个 Thrift 服务。旨在无缝兼容HiveServer2。因为 Spark Thrift Server 的接口和协议都和 HiveServer2 完全一致,因此我们部署好Spark Thrift Server后,可以直接使用hive的beeline访问Spark Thrift Server执行相关语句。Spark Thrift Server 的目的也只是取代 HiveServer2,因此它依旧可以和 Hive Metastore进行交互,获取到 hive 的元数据。
- Spark Thrift Server和HiveServer2的区别
- 总结:Spark Thrift Server说白了就是小小的改动了下HiveServer2,代码量也不多。虽然接口和HiveServer2完全一致,但是它以单个Application在集群运行的方式还是比较奇葩的。可能官方也是为了实现简单而没有再去做更多的优化。

Spark SQL编程
- SparkSession是spark最新的SQL查询起始点
DataFrame
- 创建DataFrame
- 通过spark的数据源进行创建
- 如果从内存中读取数据,spark可以知道是什么数据类型,如果是数字,默认做Int处理;但是从文件中读取的数字,不能确定是什么类型,所以用bigint接收,可以和Long类型转换,但是和Int不能进行转换。
- 从一个存在的RDD进行转换
- 从hive Table进行查询返回
- 通过spark的数据源进行创建
- SQL风格语法:是指我们查询数据的时候使用SQL语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助。
- DSL风格语法:DataFrame提供一个特定领域语言(domain-specific language,DSL)去管理结构化的数据,可以在Scala,Java,Python和R中使用DSL,使用DSL语法风格不必再创建视图了。
DataSet
- DataSet是具有强类型的数据集合,需要提供对应的类型信息。它是和类对应起来的。
- 创建方式
- 使用样例类序列创建DataSet
- 使用基本类型的序列创建DataSet
- RDD,DataFrame转换为DataSet
RDD,DataFrame,DataSet三者之间的关系
- 三者的共性
- 都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
- 三者都有惰性,再创建,转换,等操作时不会立即执行,只有再遇到Action操作时,才会开始运算。
- 三者的区别
- RDD不支持SparkSQL操作
- DataFrame每一行的类型固定为Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值。
- DataFrame是DataSet的一个特例 type DataFrame=Dataset[Row]
- DataFrame也可以叫DataSet[Row],每一行的类型Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无法得知,只能用getAS方法或者共性中的第七条提到的模式匹配拿出特定字段。而DataSet中,每一行是什么类型是不一定的,在自定义了case class之后可以很方便的获取每一行的信息。
- 三者之间的转换关系图
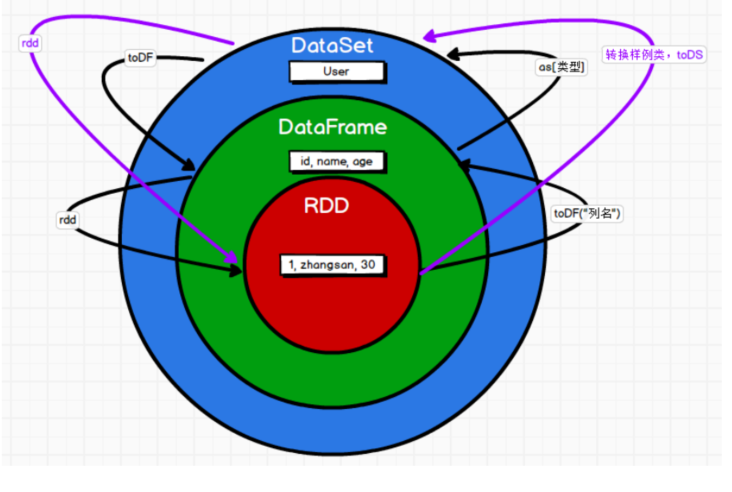
- 速记
- 转换成RDD都是rdd
- 转换成DataFrame都是toDF。RDD到DF是toDF(“列名”)
- RDD转换成DataSet是:转换样例类.toDS;DataFrame转换成是:as[类型]
- 如果需要RDD与DF或者DS之间操作,那么需要引入import spark.implicits._ (spark不是包名,而是sparkSession对象的名称,所以必须先创建SparkSession再导入对象,.implicits是一个内部的object)
Spark sql 任务优化
spark sql 任务中小文件的优化
描述:在数栈开发过程中如果任务选择的是spark sql引擎,一定要注意减少小文件的输出。spark sql中 spark.spl.shuffle.partitions=200 ,即会在shuffle结果中产生200个文件,设置的是RDD1做shuffle处理后生成的结果RDD2的分区数。这样产生的影响有:大部分时间都花费在调度,任务执行本身花费时间较小;最终产生的小文件数过多,会对后续任务的使用造成资源浪费,且严重影响namenode的性能。如果结果数据不多且预计增量不会太大(例如缓慢变化维表,码值表等),可以将此参数数值设低。
解决:针对数据量变化较大的任务,可以通过以下参数动态调节shuffle.partition 的个数产生及小文件个数的产生。
针对数据量变化较大的任务,可以通过以下参数动态调节shuffle.partition的个数产生及小文件个数的产生。spark sql 小文件合并参数。
- spark.sql.adaptive.enabled=true
- spark.sql.adaptive.shuffle.targetPostShuffleInputSize=256000000 #hdfs中block大小的倍数。
以上参数只对宽依赖产生作用(join,groupby ,distribute by,order by 等),如果没有用到宽依赖的关键字,比如只用了union all,可以在sql代码最后添加distribute by 关键字,如:distribute by 1
任务中是否产生了小文件信息可以通过以下方法查看:
通过hdfs_namenode的web页面进行查看,默认端口为50070
登录namenode节点,通过类似命令查看:
1
hdfs dfs -du -h /dtInsight/hive/warehouse/${项目名称.db}/${表名}/pt=${分区}/
用户自定函数
- UDF(User-Defined-Function) 用户自定义函数 (一进一出)
- UDAF(User-Defined Aggregation Function)用户自定义聚合函数(多进一出)如 count(),countDistinct(),avg(),max(),min()
- 实现:通过继承UserDefinedAggregateFunction来实现用户自定义聚合函数
- UDTF(User-Defined Table-Generating Functions)用户自定义表生成函数 (一进多出) Spark中没有UDTF,spark中使用flatMap实现UDTF的功能
数据加载与保存
- spark.read.load 是加载数据的通用方法
- df.write.save 是保存数据的通用方法
Spark Streaming
Spark Streaming概述
- 离线计算:就是在计算开始前就已知所有输入数据,输入数据不会产生变化,一般数据量大,计算时间也较长。最经典的就是Hadoop的MapReduce方式。
- 实时计算:输入数据是可以以序列化的方式一个个输入并进行处理的,也就是说在开始的时候不需要知道所有数据,与离线计算相比,运行时间短,计算量级相对较小。强调计算过程的时间要短,即所查当下给出结果。
- 数据处理的方式
- 批:处理离线数据,冷数据。单个处理数据量大,处理速度比流慢。
- 流:在线,实时产生的数据。单次处理的数据量小,但处理速度更快。
- Spark Streaming 用于流式数据的处理。
- Spark Streaming使用了一个高级抽象离散化流(discretized stream),叫做DStream。
- DStreams是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为RDD存在,而DStream是由这些RDD所组成的序列(因此得名“离散化”)
- Spark Streaming 是一种“微量批处理”架构,和其他基于”一次处理一条记录”架构的系统相比,他的延迟会相对高一些。
- 背压机制:根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。
DStream
- DataFrame创建
- 使用ssc.queueStream(queueOfRDDs)来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream处理。
- 自定义数据源:继承Receiver,并实现onStart,onStop方法来自定义数据源采集。
- Kafaka数据源
- kafka 0-10 Direct模式
- Executor读取数据并计算
- 增加Executor个数来增加消费的并行度
- offset存储
- _consumer_offsets系统主题中,Kafka中的内部主题
- 手动维护(有事务的存储系统)
- kafka 0-10 Direct模式
- DStream转换
- 与RDD类似,分为Transformations(转换)和Output Operations(输出)两种
- Transformations(转换)
- 无状态转换操作就是把简单的RDD转化操作应用到每个批次上,也就是转化DStream 中的每一个RDD。不会记录历史结果
- 有状态转换操作:
- UpdateStateByKey 算子用于将历史结果应用到当前批次,该操作允许在使用新信息不断更新的同时能保留它的状态。保留历史结果到下一次计算。
- window 窗口操作。 窗口时长:计算内容的时间范围。滑动时长:间隔多久触发一次计算。这两者都必须为采集周期的整数倍。
- DStream输出
- print() 在运行流程序的驱动结点上打印DStream中每一批次数据的最开始10个元素。这用于开发和调试。
- foreachRDD(func) 即将函数func用产生于stream的每一个RDD,其中参数传入的函数func应该实现将每一个RDD中数据推送到外部系统。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!