conclusion
本文最后更新于:2024年9月30日 晚上
重点知识点总结
Linux
linux常用命令
序号 命令 命令解释 1 top 查看内存 2 df -h 查看磁盘存储情况 3 iotop 查看磁盘IO读写情况,要root权限 4 iotop -o 直接查看比较高的磁盘读写程序 5 netstat -tunlp | grep 端口号 查看端口占用情况 6 uptime 查看报告系统运行时长及平均负载 7 ps -aux 查看进程 ifconfig 查看IP地址
ps -aux 显示USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ps -ef | grep flume 查看进程和父进程的ID(flume进程的关闭就可以通过此方式查看进程号)
ps -ef 显示 UID PID PPID C STIME TTY TIME CMD
PID是程序被操作系统加载到内存成为进程后动态分配的资源,每次程序执行的时候,操作系统都会重新加载,PID在每次加载都是不同的。
PPID 是程序的父进程号
Shell
框架启动关闭脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14#!/bin/bash
case $1 in
"start"){
for i in hadoop100 hadoop101 hadoop102
do
ssh $i "启动命令,用绝对路径"
done
};;
"stop"){
};;
esac单引号和双引号的区别
- 单引号:’$do_date’,在引号内部的变量不能解释里面变量对应的值
- 双引号:”$do_date”,在引号内部,能够取出变量的值
- 单引号,双引号嵌套:看谁在最外面
- ``号表示,执行引号中的命令
Hadoop
基础知识
- Hadoop3.x常用端口
- namenode rpc 端口 8020 2.x是9000
- namenode http 端口 9870 2.x是50070
- resourcemanager webapp.address 端口8088
- 19888 历史服务器
- 安装配置文件
- core-site.xml
- yarn-site.xml
- mapred-site.xml
- hdfs.site.xml zk信息在此配置
- workers(3.x) slaves(2.x)
HDFS
- HDFS块大小2.x,3.x,默认都是128M 本地模式32M
- 块大小主要看服务器之间的传输速率
- HDFS读写流程
- 写数据流程(8步)
- 客户端向NameNode请求写入数据
- NameNode响应是否上传文件
- 客户端上传第一个Block的信息
- namenode返回datanode节点(dn1,dn2,dn3)
- 客户端与datanode建立连接通道
- datanode逐级应答
- 客户端向dn1传输数据(以Packet的形式64kb),dn1再向dn2传输,依次传输。dn1每传输一个packet会放入一个应答队列等待应答.
- 重复3-7步,传输block2
- 读数据流程(4步)
- 客户端向Namenode请求读数据
- namenode返回元数据信息
- 找最近的datanode
- datanode向客户端传输信息,以packet 的形式。
- 写数据流程(8步)
MapReduce
- shuffle流程以及优化
- map方法之后,redece方法之前的数据处理过程
- 大致流程
- MapTask收集map()方法的K,V对,并将这些数据放入环形缓冲区中
- 当环形缓冲区(默认100m)达到80%后,会进行溢写操作,将数据反向溢写到磁盘。在环形缓冲区中会进行快速排序。如果数据阻塞了,会暂停向环形缓冲区写数据。
- 会将溢写到磁盘的文件进行归并排序,在溢写和归并的过程中,都要调用Partitioner进行分区和针对key进行排序。框架调用Partitioner分区器分区(指定分区规则),WritableComparable排序器排序(指定排序规则)。
- ReduceTask 会根据分区号,去各个MapTask上取相应的结果分区数据。将数据写入内存
- ReduceTask会取到同一分区来自不同MapTask的结果文件,内存不够时,也会触发溢写操作,将数据写入磁盘。
- ReduceTask会将这些文件进行合并(归并排序)还可以将归并完成的文件看需求是否进行分组操作(GroupingComparator分组),合并成大文件后,shuffle过程结束。之后将数据按reduce 方法去处理。
- 优化:
- 自定义分区(减少数据倾斜)
- 可以设置环形缓冲区到90%,95%之后再进行溢写,减少溢写文件,提升速度
- 再不影响业务逻辑的情况下(如求和),可以进行Combiner操作。对MapTask的输出进行一个局部汇总
- 在MapTask中,默认一次归并10个文件,可以设置更多提高性能
- MapTask输出可以进行压缩(snappy ,lzo),减少数据传输量,提升速度
- ReduceTask一次默认拉取5个MapTask同一分区的数据,可以根据集群性能调整
- ReduceTask从MapTask中拉取数据先放入内存中,可以适当提高内存,减少溢写,也增加传输速度
- 一般情况下1g内存 对应128M数据 比较合理
- NM默认内存:8g(服务器调整到100g左右)
- 单个任务默认内存:8g
- MapTask默认内存:1g
- ReduceTask默认内存:1g
- MapJoin:在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。mapjoin适合一张表很大,一张表很小的场景。将小表缓存
- 在Mapper的setup阶段(重写setup方法),将文件读取到缓存集合中
- 在驱动函数中加载缓存,缓存普通文件到Task运行节点
- job.addCacheFile(new URL(“file://e:/cache/xxx.txt”))
YARN
Yarn是一个资源调度平台,负责为运算程序提供服务运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算则相当于运行于操作系统之上的程序。
yarn工作调度流程(8步)
客户端执行job.waitForCompletion
客户端向RM申请运行一个Application
RM向client 返回Application的资源提交路径和job_id
client将资源(切片信息,配置信息,所需jar包)提交到HDFS上
资源提交完成,Application向RM申请运行AppMaster
AppMaster下载Client提交的资源到本地
APPMaster向RM申请多个任务资源,运行MapReduce程序
运行完成后,MR会向RM申请注销自己。
yarn资源调度器
- FIFO
- 队列形式,先进先出
- 容量调度器(默认的资源调度器)
- 几个并行的FIFO,当资源不紧张时,采用此方式
- 优先满足先进入的任务
- 公平调度器 (能最大限度的利用集群资源)
- 最大限度的利用集群资源
- 每个任务都公平的享有资源,并发度高
- 同一队列的作业按照其优先级分享整个队列的资源,并发执行
- 每个作业可以设置最小资源值,调度器会保证作业获得其以上的资源
- FIFO
优化问题
- 优化问题
- 小文件问题
- har归档
- 使用CombineTextInputformat
- JVM重用
- 数据倾斜问题
- 启用combiner ,减少数据的传输量
- 根据数据分布情况,自定义分区,将key 均匀分配到Reducer
- 重新设计key,有一种方案是在map阶段时给key加上一个随机数,有了随机数的key就不会被大量的分配到同一节点(小几率),待到reduce后再把随机数去掉即可。
- 增加Reducer,提升并行度
- 增加JVM内存
- 小文件问题
Zookeeper
Zookeeper从设计模式的角度理解,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应
Zookeeper=文件系统+通知机制
选举机制
奇数台
10台服务器:3台
20台服务器:5台
100台服务器:11台
台数不是越多越好,太多选举时间过长影响性能。
zk半数以上可以正常运行
ZooKeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目
常用命令
- ls path 查看当前znode中所包含的内容
- create 普通创建 -s含有序列 -e 临时(重启或超时消失)
- get path 获得节点的值
- set 设置节点的具体值
- stat 查看节点状态
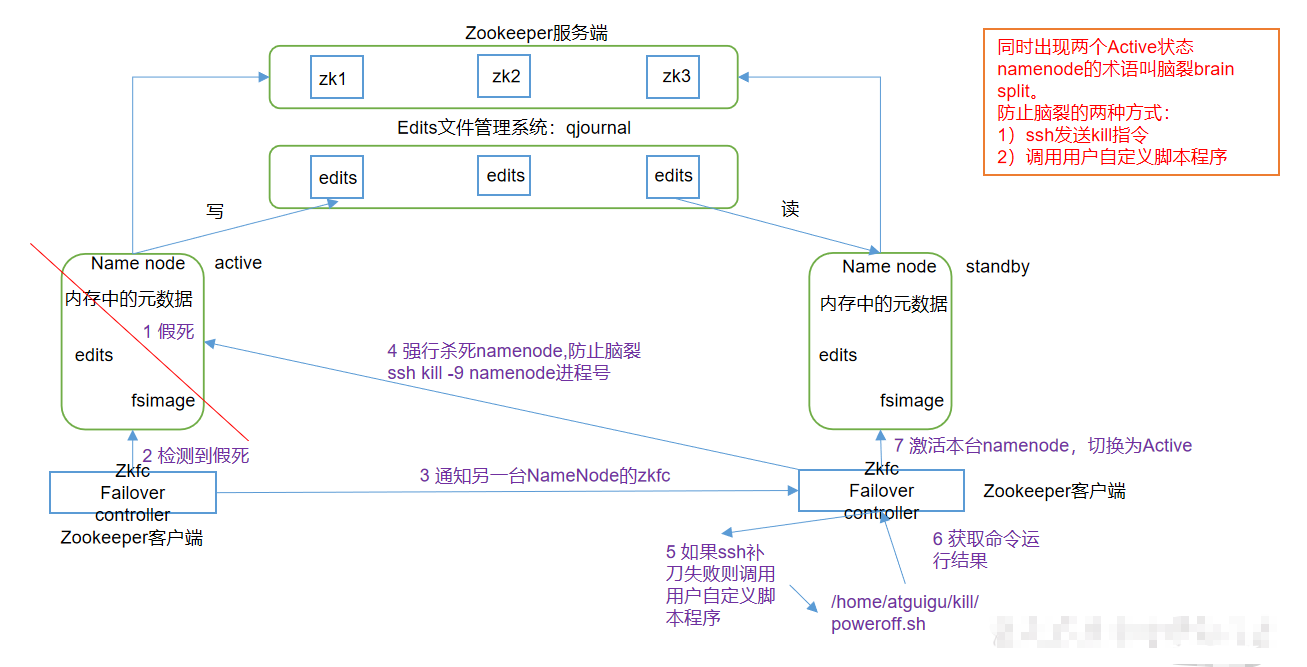
HA
Flume
架构
flume是一个分布式的海量日志采集,聚合,和传输的系统
Flume agent 内部原理
source接收数据,数据以event的形式传给ChannelProcessor
ChannelProcessor将事件传递给拦截器,在拦截器中可以对event数据进行更改
经过拦截器后,数据返回到ChannelProcessor,ChannelProcessor将每个event交给ChannelSelector,ChannelSelector的作用就是选出Event将要发往哪个Channel,有两种选择:分别是Replicating(复制)和Multiplexing(多路复用)
数据再返回到ChannelProcessor,根据选择器的选择,进入不同的Channel
SinkProcessor再决定channel中的event 的走向
SinkProcessor共有三种类型,分别是DefaultSinkProcessor、LoadBalancingSinkProcessor和FailoverSinkProcessor
DefaultSinkProcessor对应的是单个的Sink,LoadBalancingSinkProcessor和FailoverSinkProcessor对应的是Sink Group,LoadBalancingSinkProcessor可以实现负载均衡的功能,FailoverSinkProcessor可以错误恢复的功能(故障转移)。
event:flume传输数据的基本单位,由Header和Body组成,Header用来存放该event的一些属性,为K,V结构(Header不设置的话为空);Body用来存放该条数据,形式为字节数组。
source
- Taildir Source:适用于监听多个实时追加的文件,并且能够实现断点续传。(可能会出现数据重复)
- batchSize参数决定Source一次批量运输到Channel的event条数,适当调大这个参数可以提高Source搬运Event到Channel时的性能。
channel
- File Channel 基于磁盘 可以存100万个event
- Memory Channel 基于内存 可以存100个event
- KafkaChannel 数据存储在Kafka里面 基于磁盘的 KafkaChannel传输性能大于MemoryChannel+KafkaSink
sink
- hdfs sink
- 针对小文件 hdfs sink 有优化的参数
- hdfs sink
拦截器
- 自定义拦截器
- 定义类实现Interceptor接口,重写四个方法(初始化,单event修改,多event修改,关闭资源) 还需要一个Builder静态内部类,实现Interceptor.Builder,在里面new一个自定义的拦截器返回。
- 自定义拦截器
选择器(Channel Selector)
- Multiplexing(多路复用)可以选择传到指定的Channel 上
- Replicating(复制) event传到每个Channel上
监控器
- 监控资源的读写情况
调优
- filechannel 能多磁盘就配置多磁盘(数据保存到不同磁盘) 能提高吞吐量
- hdfs sink 小文件问题 设置 每个文件的滚动大小(128m)多久创建一个新的文件(1-2小时) event个数(0)设置为0表示文件的滚动与event 数量无关
Kafka
基本信息
Kafka是一个分布式的基于发布/订阅模式的消息队列
架构
- producer: 消息生产者,向Kafak集群发消息的客户端
- Kafka Cluster:Kafka集群
- consumer: 消息消费者,向Kafka Broker取消息的客户端
- consumer group:消费者组,每个消费者组由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个消费者消费。消费者组之间互不影响,所有消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- broker :Kafka集群中的每一台机器就是一个broker ,一个Kafka集群由多个broker 组成。
- topic: 可以理解为一个消息队列,生产者和消费者面向的都是一个个topic。一台broker 可以容纳多个topic
- partition:一个topic可以分为多个partition,每个partition都是一个有序的队列。可以实现很好的扩展性,一个非常大的topic可以分布到多个broker上。
- replica:副本,保证数据的可靠性。即当集群中的某个节点发生故障时,为保证数据的完整性,kfak提供了副本机制,一个topic的每个partition都有若干个副本,一个leader和若干个follower
- leader:副本的”主“,生产者发送数据的对象,以及消费者消费数据的对象都是leader
- follower: 副本中的”从“,实时从leader中同步数据,保持和leader数据的同步,leader发生故障时,会选出某个follower成为新的leader
分区策略
- 分区原因(为什么将一个topic分为多个partition):1. 方便在集群中扩展。2. 以partition为单位进行读写,可以提高并发。
分区分配策略
- 确定哪个partition由哪个consumer来消费
- round-robin:当分区数大于consumer数量时,轮询分配,类似于斗地主一张一张的发牌。
- range:类似于斗地主一次性发几张牌
挂了
- 短时间 会存储在flume channel里
- 长时间 日志服务器有30天数据
丢了
- ack 的几种情况(三种)
- producer向Kafka集群发送信息是异步通信,为保证数据的可靠性,需要向producer发送ACK(acknowledgement 回信),如果producer收到ack,就进行下一轮的发送,否则重新发送数据。此时会出现三种情况
- 0 收到后还没开始写就发送,最不安全
- 1 leader写完后发送
- all(-1) ISR中所有副本都写完后发送ack
- ISR队列(在第三中情况下,为了防止某个follower长时间未向leader同步数据,该follower会被踢出ISR,leader故障则会重选leader)
- 和leader保持同步的follower在ISR中,一定时间不同步会被提出ISR,时间阈值由replica.lag.time.max.ms参数设定,leader故障则重新选举leader。(Leader选举由Zookeeper来完成)
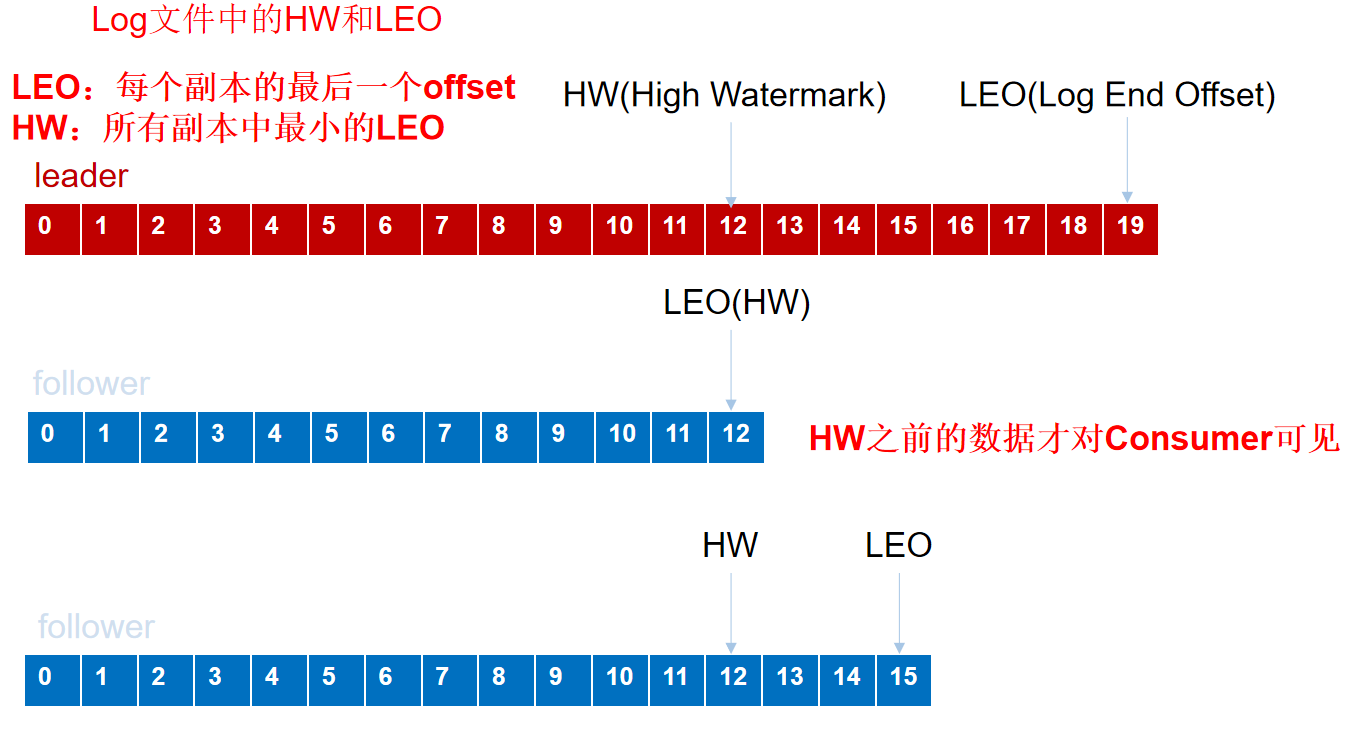
- 当follower故障时会被临时踢出ISR,待待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
- leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
- 这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复
- At Least Once可以保证数据不丢失,但是不能保证数据不重复
重复了
- (自己解决)幂等性,事务,ack=-1
- (其它框架帮忙解决)数仓里面处理,
积压了
- 如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费者组的消费者数量,消费者数=分区数。
- 增加下一级的消费速度
优化
- 由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
- 将offset放在Kafka内置的一个topic中,__consumer_offsets。由50个分区。
- Broker 参数配置,保留三天,也可以更短
- Replica相关配置 ,默认副本一个
- 网络不稳定时,可以将网络通信延时
- producer优化 采用压缩
- 增加kafka内存 生产环境下尽量不要超过6G
其它
Exactly once语义:At Least Once + 幂等性 = Exactly Once。
幂等性就是指Producer不论向Server发送多少次重复数据,Server端都只会持久化一条。
将服务器的ACK级别设置为-1,可以保证Producer到Server之间不会丢失数据,即At Least Once语义。
要启用幂等性,只需要将Producer的参数中enable.idompotence设置为true即可。Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。而Broker端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会持久化一条。
局限性:但是PID重启就会变化,同时不同的Partition也具有不同主键,所以幂等性无法保证跨分区跨会话的Exactly Once。
要实现跨分区的Exactly Once,需要Transaction Coordinator,用于管理produce发送的信息的事务型。
- 该
Transaction Coordinator维护Transaction Log,该log存于一个内部的Topic内。由于Topic数据具有持久性,因此事务的状态也具有持久性。 - 应用程序必须提供一个稳定的(重启后不变)唯一的ID,也即
Transaction ID。Transactin ID与PID可能一一对应。区别在于Transaction ID由用户提供,而PID是内部的实现对用户透明。 - 有了
Transaction ID后,Kafka可保证:- 跨Session的数据幂等发送。当具有相同
Transaction ID的新的Producer实例被创建且工作时,旧的且拥有相同Transaction ID的Producer将不再工作。 - 跨Session的事务恢复。如果某个应用实例宕机,新的实例可以保证任何未完成的旧的事务要么Commit要么Abort,使得新实例从一个正常状态开始工作。
- 跨Session的数据幂等发送。当具有相同
- 该
Kafka高效读写的原因
Kafka是分布式,还可以设置分区,并发度高
采用顺序读写,topic在磁盘中顺序存储
零拷贝技术
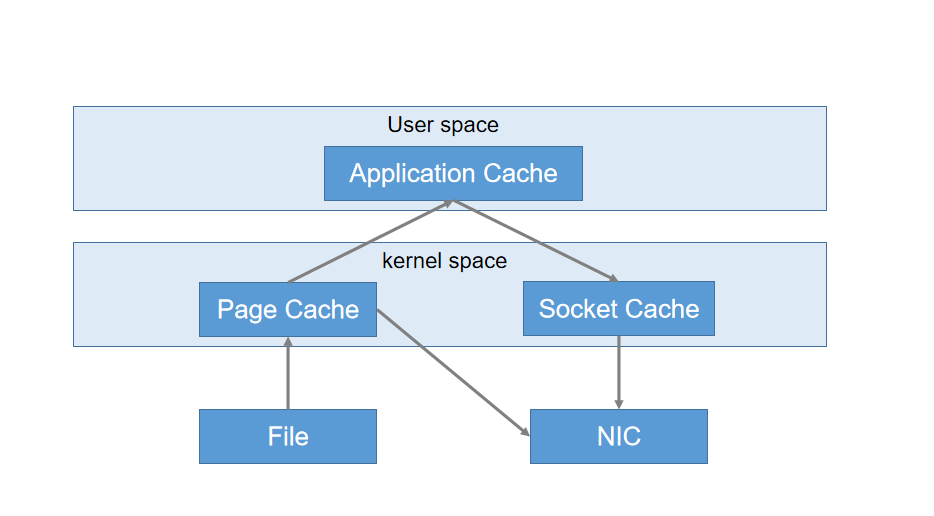
直接将文件从内核层拷贝到目标地址。速度更快
Zookeeper在Kafka中的作用
- Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。Controller的管理工作是依赖于Zookeeper的。
Hive
组成
数据类型转换
CAST: CAST ( expression AS data_type )
select cast(1000 as varchar(10)) cast(1000 as varchar) cast('1000' as int)1
2
3
4
5
- CONVERT: CONVERT (data_type[(length)], expression [, style])
````sqlite
select convert(datetime,'2017-01-01')
与Mysql的区别
- 数据量 hive擅长大数据场景 mysql擅长小数据场景(数据超过一千万条后速度就不行了)
- 速度 大数据场景下 hive快 小数据场景下 mysql 快
内部表和外部表的区别
- 内部表 删除后,元数据和表中的数据(原始数据)都删除了
- 外部表 删除后,只删除了元数据
插入数据
- insert into :以追加数据的方式插入到表或分区,原有数据不会删除
- insert overwrite:会覆盖表或分区中已经存在的数据
4个by
- order by 全局排序(都会进入一个Reduce)很容易造成数据倾斜
- sort by 局部排序(对每个reduce排序)
- distribute by 分区,按照分区进入不同的reduce
- cluster by 当sort by 和distribute by 排序的字段相同时可以使用 cluster by 代替(默认只能是升序)
系统函数
常用内置函数
date_add
- 返回日期的后n天的日期
- select date_sub(‘2015-04-09’,4);输出2015-04-13
date_sub
- 返回日期前n天的日期
- select date_sub(‘2015-04-09’,4);输出:2015-04-05;
next_day
- 返回当前时间的下一个星期几对应的日期
- select next_day(‘2018-02-27 10:03:01’, ‘TU’); –2018-03-06
- 说明,输入日期为2-27,下个星期的周二为03-06,如果想要知道下周一的日期就是MO,周日就是SU,以此类推。
- 注意:西方都是任务周日是每周的第一天
date_format
‘yyyy-MM-dd HH:mm:ss’ 日期格式:年月日 时分秒
日期格式化,把字符串或者日期转成指定格式的日期
date_format(“2016-06-22”,”yyyy-MM-dd”)=2016-06-22
last_day
- 返回这个月的最后一天的日期
- select last_day(“2021-10-04”);=2021-10-31
解析json(get_json_object)
1
2
3
4
5
6
7SELECT get_json_object('[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]',"$[0].age");
- 结果:25
select get_json_object('[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]','$[0]');
- 结果:{"name":"大郎","sex":"男","age":"25"}
自定义函数
- UDF 解析公共字段(定义类 继承UDF,重写evaluate 方法)
- UDTF 解析事件字段 (定义类 继承UDTF,重写3个方法,分别是初始化(定义返回值的名称和类型),process,关闭)
窗口函数
- 窗口函数:指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化变化。(查询的数据会随着where,gruopby,having等条件的加入过滤掉一些数据)
- rank()排名会重复,重复数据的话,排名数不会连续,排名数和总数一样,dense_rank() 相同的排名一样,数据重复的话排名数会比总数少。row_number() 直接排名,相同排名也不一样,排名数和总数一样。
- over((partition by xxx order by xxx)
- 手写topn
优化
sql优化
- 大表对大表:尽量减少数据集,可以通过分区表,避免扫描全表或者全字段
- 大表对小表:设置自动识别小表,将小表放入内存中去执行
mapjoin 默认打开 ,不要关闭
先执行where再执行join,可以通过先where过滤一部分数据,再进行连接
创建分区表(天)
小文件相关处理
- CombinehiveInputformat ===>减少切片个数,减少maptask个数
- JVM重用
- 使用concatenate命令 alter table B partition(day=20201224) concatenate;
- ALTER TABLE A ARCHIVE PARTITION(dt=’2021-05-07’, hr=’12’);
不影响业务逻辑的情况下可以开启map端combiner
merge 如果是map only任务,默认打开,执行完任务后,会产生大量小文件,默认会帮你开启一个job,将小于16M的文件,合并到256M。如果是mapreduce任务,需要将该功能开启
压缩
列式存储
替换引擎
- MR
- TEZ
- SPARK
union会去重,union all 不会去重
hive数据倾斜
set hive.groupby.skewindata=true 生成两个MRJOB,第一个MR,先随机打散key,减少数据倾斜。第二个MR,再根据预处理的数据结果按照Group By Key分布到reduce中,最终完成z
Java SE
- HashMap的底层源码,数据结构
- 在JDK1.8中,HashMap由数组+链表+红黑树实现
- 链表长度大于8,且表的长度大于64的时候将链表转化为红黑树
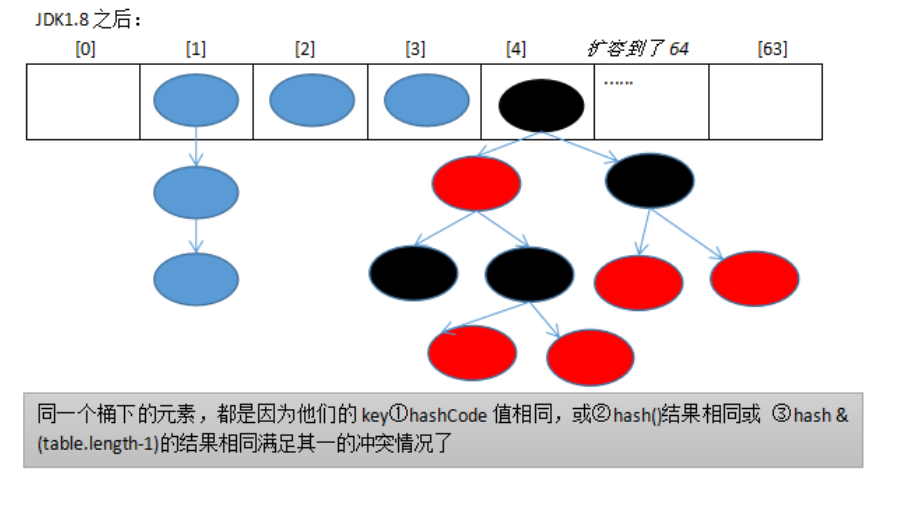
- 红黑树其实就是一种自平衡的二叉查找树。
- HashMap和HashTable
- 线程安全性不同
- HashMap是线程不安全的,HashTable是线程安全的,其中的方法是Synchronize的,在多线程并发的情况下,可以直接使用HashTable,但是使用HashMap是必须自己增加同步处理。
- key和value是否允许null值
- HashTable中,key和value都不允许出现null值。HashMap中,null可以作为键,这样的键只有一个,可以有一个或多个value值为null。
- 数组初始化和扩容机制
- HashTable在不指定容量的情况下默认容量为11,而HashMap为16。
- HashTable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的两倍。
- 线程安全性不同
- StringBuffer和StingBuilder的区别
- StringBuffer是线程安全的,而StringBuilder是线程不安全的
- 单线程程序下,StringBuilder效率更快,因为它不需要加锁,而StringBuffer则每次都需要判断锁,效率相对更低。
- String和StringBuffer的区别
- String类是final修饰的,它是一个字符串常量,因此它一旦创建,其内容和长度不可改变,StringBuffer类它的内容和长度都是可变的。
- String类重写了equals()方法,StringBuffer没有
- String类对象之间可以用“+”号连接,StringBuffer对象之间不能。
- Final,Finally,Finalize
- final:修饰符(关键字)有三种用法:修饰类,变量和方法。修饰类时,意味着它不能被继承。修饰变量时,该变量使用中不被改变,必须在声明时给定初值。修饰方法时,同样只能使用,不能在子类中被重写。
- finally:通常放在try{}catch 的后面构造最终的执行代码块。这就意味着程序无论正常执行还是发生异常,这里的代码只要JVM不关闭都能执行。
- finalize:Object类中定义的方法,Java中允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在销毁对象时调用的,通过重写finalize()方法可以整理系统资源或者执行其它清理工作。
- ==和equals的区别
- ==:如果是比较基本数据类型,那么比较的是变量的值。如果比较的是引用数据类型,那么比较的是地址值(两个对象是否指向同一块内存)
- equals:如果类没重写equals方法比较的是两个对象的地址值,如果类重写了equals方法后我们往往比较的是对象中属性的内容。
- equals方法是从Object类中继承的,默认的实现就是使用==
- 常见执行顺序
- 父类静态代码块——>子类静态代码块——>父类代码块——>父类构造方法——>子类代码块——>子类构造方法
- ArrayList,HashMap扩容机制
- ArrayList初始化大小为0(第一次调用add 方法后长度变为10),当节点不够用时,就会扩容。扩容后的大小=原始大小*1.5
- HashMap:初始化大小是16,扩容因子默认为0.75(可以指定初始化大小,和扩容因子)
- 扩容机制:当前大小和当前容量的比例超过了扩容因子,就会扩容,扩容大小增大一倍。
- Java接口和抽象类
- 含有抽象方法的类必须定义为抽象类,但抽象类中可以不包含任何抽象方法。抽象类不能被实例化,只能通过子类来实现。
- 接口将抽象进行的更加彻底,在JDK1.8中,接口中除了可以有抽象方法外,还可以有常量,默认方法和静态方法(类方法),默认方法用default修饰,静态方法用static修饰,且这两种方法都允许有方法体。
- volatile关键字能否保证线程安全
- 单纯使用volatile关键字是不能保证线程安全的
- volatile只提供了一种弱的同步机制,用来确保将变量的更新操作通知到其他线程
Spark
Spark架构与作业提交流程
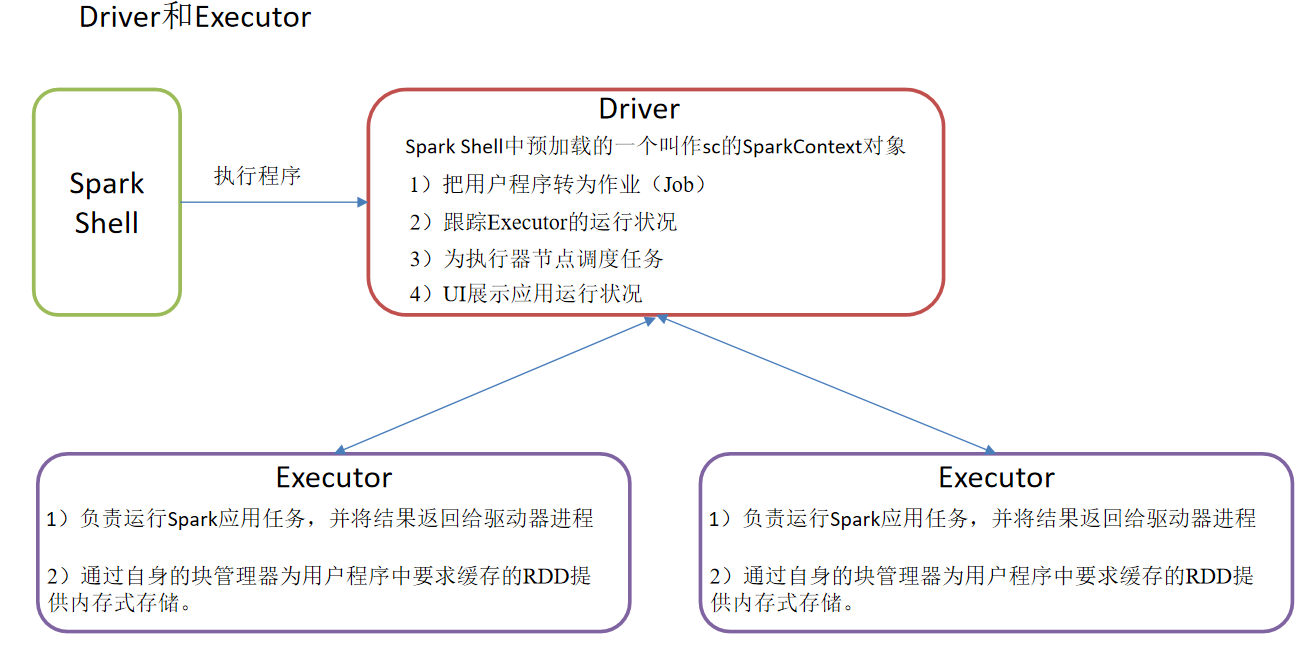
Yarn Cluster模式
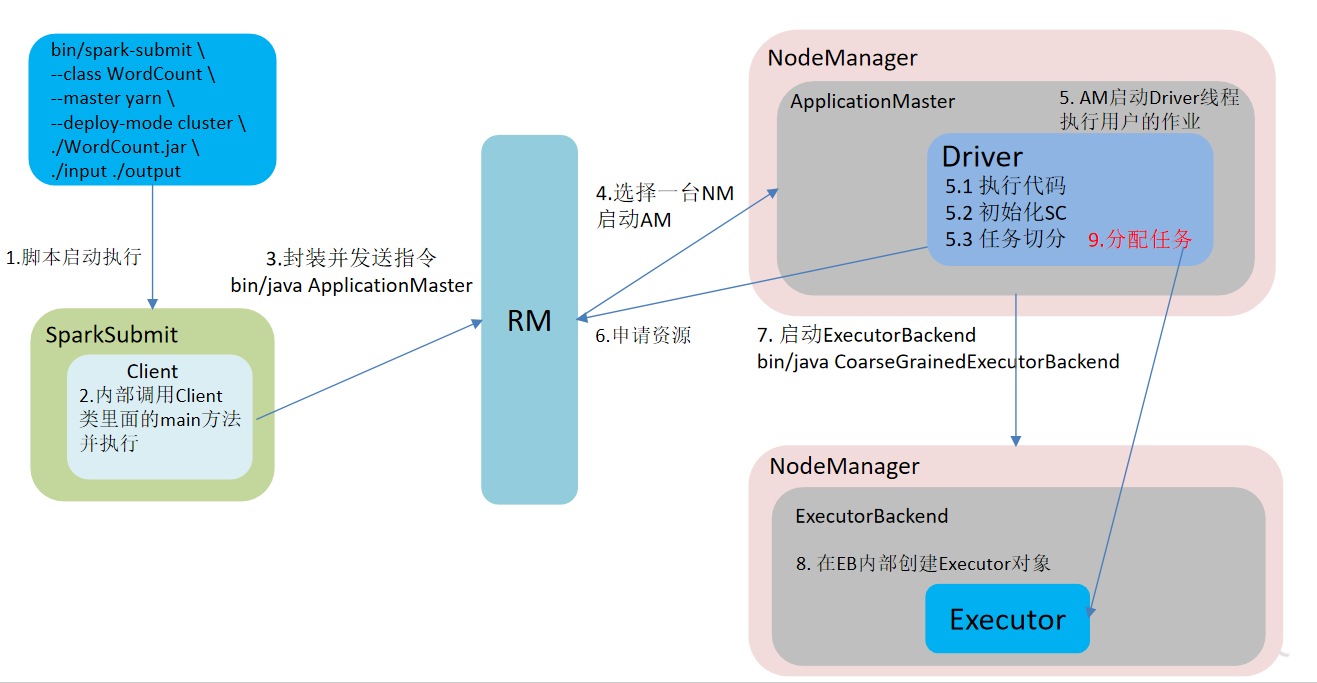
- 脚本启动执行
- 调用Client类中的main方法并执行
- 调度器调度到该任务后,向RM申请资源运行ApplicationMaster,
- 选择一台NodeManager申请资源,启动AM
- AM启动Driver线程执行用户的作业
- Driver向RM申请资源
- 在NM中创建Excutor对象
常见算子
- ReduceByKey和GroupByKey的区别
- ReduceByKey按照Key进行聚合,会在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]
- GroupByKey:按照Key进行分组,直接进行shuffle
- ReduceByKey会有预聚合的操作,所以在不影响业务逻辑的情况下优先使用ReduceByKey。
- Repartition和Coalesce的关系与区别
- 关系:两者都是用来改变RDD的partition数量的,Repartition底层调用coalesce((numPartitions, shuffle = true)
- 区别:Repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle。
- 一般增大RDD的partition数量时使用repartition,减少partition数量时使用coalesce
- coalesce 一般用于缩减分区,默认不执行shuffle
- reparation 一般用于扩大分区,默认执行shuffle,底层调用的就是coalesce
Shuffle
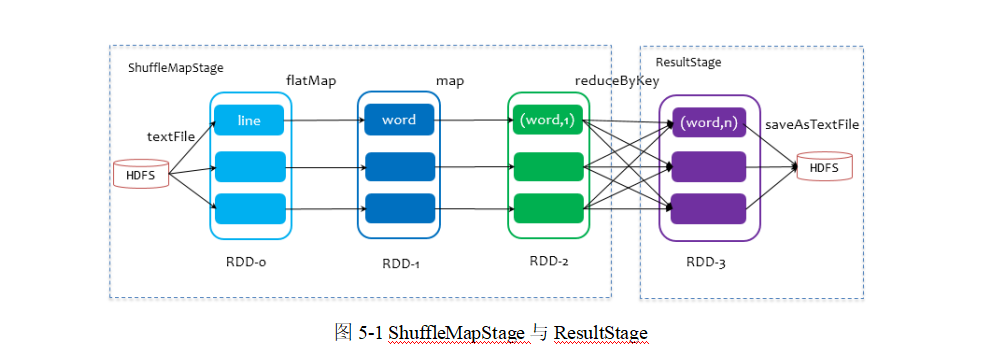
- 在划分stage时,最后一个stage称为finalStage,它本质上是一个ResultStage对象,前面的所有stage被称为ShuffleMapStage。
- ShuffleMapStage的结束伴随着shuffle文件的写磁盘
- ResultStage基本上对应代码中的action算子,即将一个函数应用在RDD的各个partition的数据集上,意味着一个job的运行结束。
- ReduceByKey和GroupByKey的区别
Task个数:
- map端的task个数等于分区数
- reduce端的stage默认取spark.default.parallelism这个配置项的值作为分区数,如果没有配置,则以map端的最后一个RDD的分区数作为其分区数(也就是N),那么分区数就决定了reduce端的task的个数。
Reduce端读取数据
map task 执行完毕后会将计算状态以及磁盘小文件位置等信息封装到MapStatus对象中,然后由本进程中的MapOutPutTrackerWorker对象将mapStatus对象发送给Driver进程的MapOutPutTrackerMaster对象;
在reduce task开始执行之前会先让本进程中的MapOutputTrackerWorker向Driver进程中的MapoutPutTrakcerMaster发动请求,请求磁盘小文件位置信息;
当所有的Map task执行完毕后,Driver进程中的MapOutPutTrackerMaster就掌握了所有的磁盘小文件的位置信息。此时MapOutPutTrackerMaster会告诉MapOutPutTrackerWorker磁盘小文件的位置信息;
完成之前的操作之后,由BlockTransforService去Executor0所在的节点拉数据,默认会启动五个子线程。每次拉取的数据量不能超过48M(reduce task每次最多拉取48M数据,将拉来的数据存储到Executor内存的20%内存中)。
HashShuffle(已经弃用了)
- 未经优化的HashShuffle
- 对相同的key执行hash算法,从而将相同的key写入同一个文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,再溢写到磁盘文件中去。
- 下一个stage的task有多少个,当前Excutor的每个task就要创建多少份磁盘文件。如果分区数很多,则会造成大量的文件

- 优化的HashShuffle
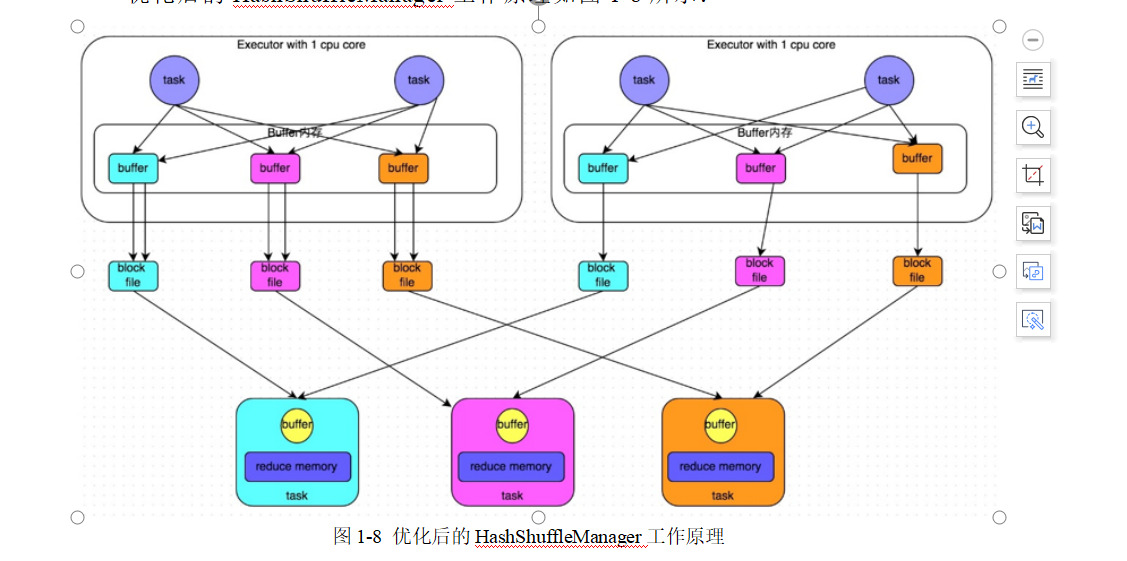
- 优化后的HashShuffle,会将一个Excutor上所有task的文件都根据key分别写入到几个磁盘文件中。几个磁盘文件取决于下层task的数量。
- 优化后的Hashshuffle减少了大量的磁盘文件。
- 不管是不是优化的hashShuffle都产生了大量的磁盘文件(都与下游的task的数量有关)。所以在高版本的spark中已经被弃用。
- 未经优化的HashShuffle
SortShuffle
SortShuffle
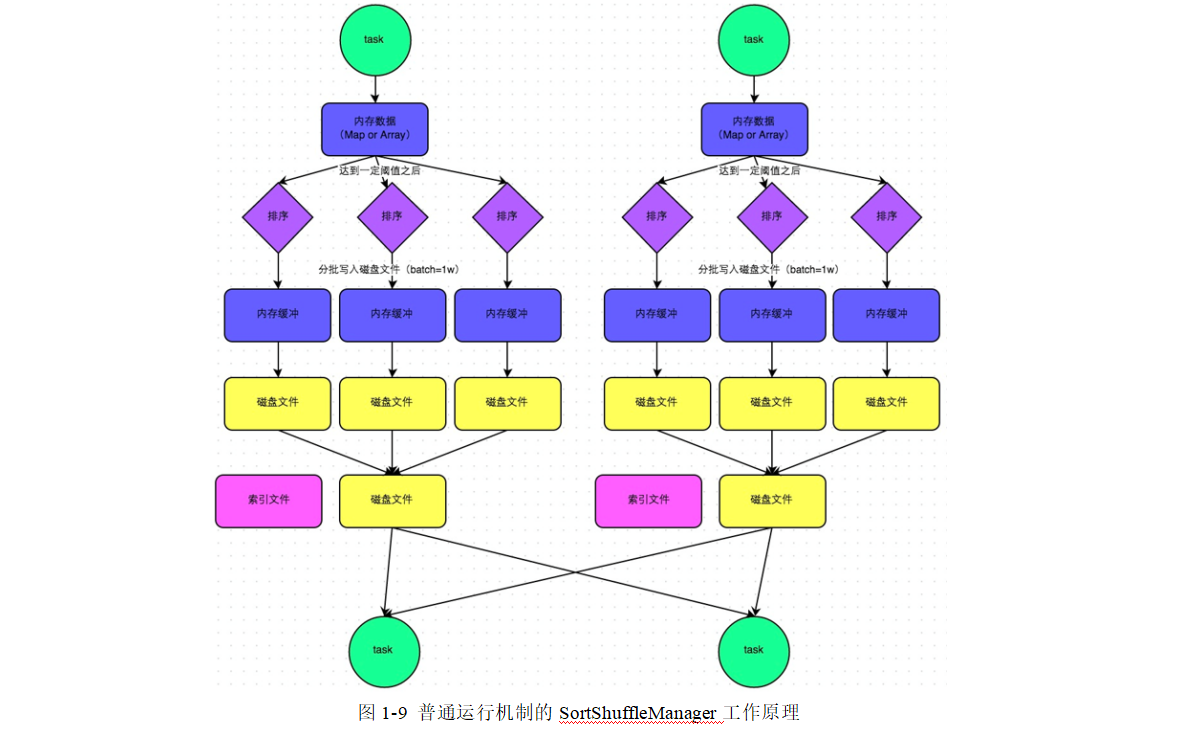
在该模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。写入磁盘文件是通过Java的BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个task就只对应一个磁盘文件,也就意味着该task为下游stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
SortShuffleManager由于有一个磁盘文件merge的过程,因此大大减少了文件数量。比如第一个stage有50个task,总共有10个Executor,每个Executor执行5个task,而第二个stage有100个task。由于每个task最终只有一个磁盘文件,因此此时每个Executor上只有5个磁盘文件,所有Executor只有50个磁盘文件
ByPassSortShuffle
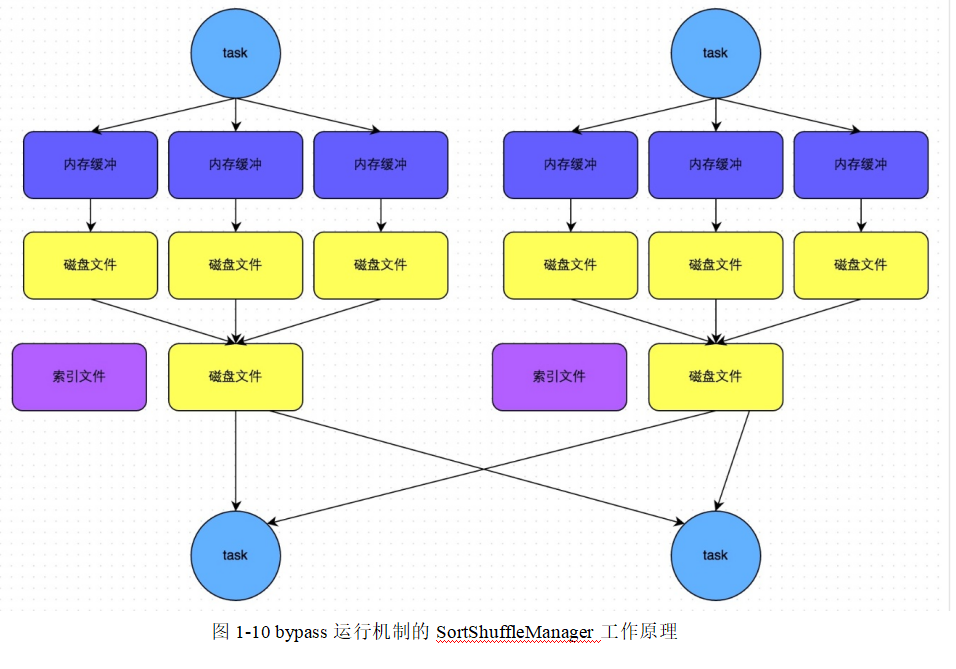
- ByPassSortShuffle运行机制的触发条件(同时满足两个条件触发)
- 不是聚合类的算子
- shuffle上一个阶段的最后一个RDD的分区数小于参数spark.shuffle.sort.bypassMergeThreshold(默认为200)(减少中间小文件产生)
- 此时,每个task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件中。写入磁盘文件也都是先写到内存缓存中,缓存写满后再溢写到磁盘文件中去。最后,会将所有的临时文件进行合并,合并成一个磁盘文件,并创建一个单独的索引文件。该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因此都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此,该机制比未经优化的HashShuffle来说shuffle read的性能会更好。
- 与普通的SortShuffle比较:
- 磁盘写机制不一样。ByPassSortShuffle每个Task会为下游都创建一个临时磁盘文件。普通的SortShuffle临时文件是溢写出来的,与下游task数量无关。
- 不会进行排序。(因此,该机制的好处就是shuffle write过程中,不需要进行数据的排序的操作,也就节省掉了这部分的性能开销。)
Spark优化
- 常规优化
- 增加资源。增加Excutor个数,增加每个Excutor的CPU core个数,增加每个Excutor的内存量。
- RDD持久化,RDD序列化。RDD尽可能早的filter操作。
- 并行度的调节,Spark官方推荐,task数量应该设置为Spark作业总CPU core数量的2~3倍。
- 使用广播变量,序列化
- 算子调优
- mapPartitions算子对RDD中的每个分区进行操作。提高了并行度。
- 在生产环境中,通常使用foreachPartition算子来完成数据库的写入,通过foreachPartition算子的特性,可以优化写数据库的性能。
- ReduceByKey算子map端预聚合
- shuffle调优
- 调节map端内存缓冲区的大小
- 调节Reduce端拉取数据内存缓冲区大小
- 调节sortshuffle排序操作阈值,如果确定业务不需要进行排序操作,可以将此参数调大一些,大于shuffle read task的数量,那么此时map端就不会进行排序了。
- 故障排除
- 控制reduce端缓冲区大小避免OOM,如果缓冲区过大,导致运算的内存不足,可能会出现OOM
- checkpoint+cache同时使用。
数据倾斜
定位数据倾斜问题:
- 查看代码中的shuffle算子,例如:distinct,reparation, reduceByKey,countByKey,GroupByKey,join等算子,根据代码逻辑判断此处是否会出现数据倾斜。
- 查看Spark作业的log文件
解决数据倾斜:
聚合原数据
- 避免shuffle过程,如果避免了shuffle过程,那么就从根本上消除了发生数据倾斜问题的可能。
- 增大key粒度,比如,原来是统计每个区的一个统计量,现在将粒度增大,变成统计一个省的某些数据。
提高reduce的并行度
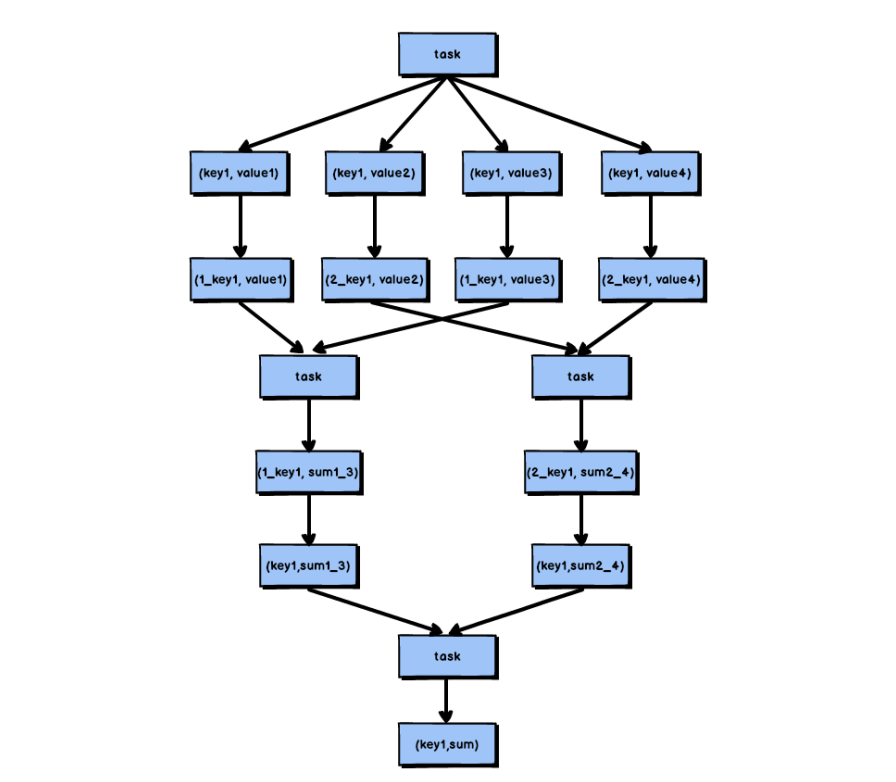
使用随机key实现双重聚合
- 当使用了类似于groupByKey,reduceByKey这样的算子时,可以考虑使用随机key实现双重聚合。
- 首先,通过map算子给每个数据的key添加随机前缀,对key进行打散,将原先一样的key变成不一样的key,然后进行第一次聚合,这样就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,随后,去掉每个key的前缀,再次进行聚合。
- 此方法仅适用于聚合类的shuffle操作
将reduce join转换成map join
- 采用广播小RDD全量数据+map算子。(RDD是不能进行广播的,只能将RDD内部的数据通过collect拉取到Driver内存然后再进行广播)
- 核心思路:将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key比较,如果连接key相同,那么就将两个RDD根据需求连接起来。
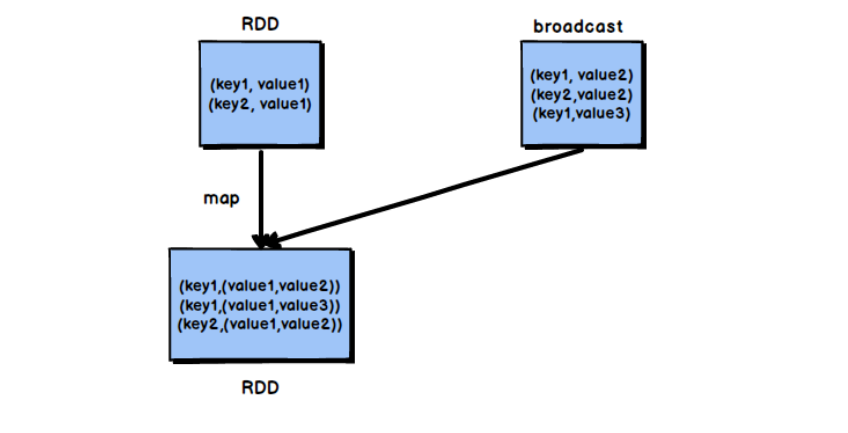
- 此方法适合小RDD和大RDD之间的join操作。与MapReduce中的mapjoin操作类似。
数仓项目分层
- ODS
- 保持数据原貌,(数据备份的作用)
- 采用压缩 LZO ==》减少磁盘空间 100g ==>10g
- 创建分区表 :==》防止后续计算时的全表扫描
- DWD
- 数据清洗
- 解析数据
- 核心字段不能为空
- 过期数据清除
- 重复数据,进行过滤
- 采用压缩,创建分区表,采用列式存储
- 维度退化
- 维度建模
- 选择业务过程
- 关心的事实表(下单,支付,点赞,收藏)
- 声明粒度
- 一行信息表示什么含义:1次,1h ,1day…..
- 根据实际情况选择,最小粒度可以统计所有指标
- 确定维度
- 维度:时间,地区,用户,商品,活动,优惠卷
- 维度退化(维度建模当中的星型模型,让事实表周围只有一级维度)
- 商品表+商品SPU表+商品SKU表+三级分类+二级分类+一级分类==》商品表
- 省份表+地区表==》地区表
- 时间表+假期表==》时间表
- 活动表+活动规则表==》活动表
- 确定事实
- 确定事实表的度量值(次数,个数,金额之类的可累加的统计值)
- 度量值的特点就是可以累加
- 通过上面的四步,结合数仓的业务事实,得出业务总线矩阵图
- 选择业务过程
- 数据清洗
- DWS
- 站在维度表的角度去看待事实,主要看事实表的度量值
- DWT
- 站在维度表的角度去看待事实
- 主要关心事实表的度量值的累加值、和累积一段时间的值,还有行为的开始时间,结束时间
- ADS
- 一些结果指标
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!