project
本文最后更新于:2023年11月16日 下午
项目总结
数据采集项目
- 项目框架版本:
- hadoop 3.1.3
- Hadoop本身不支持LZO压缩,需要下载并重新编译hadoop-lzo
- 在core-site.xml增加配置支持LZO压缩
- 创建LZO索引,LZO压缩文件可切片的特性依赖于其索引
- flume 1.9
- kafka 2.41
- Zookeeper 3.5.7
- hive 3.1.2
- spark 2.1.1
- hadoop 3.1.3
- 项目架构
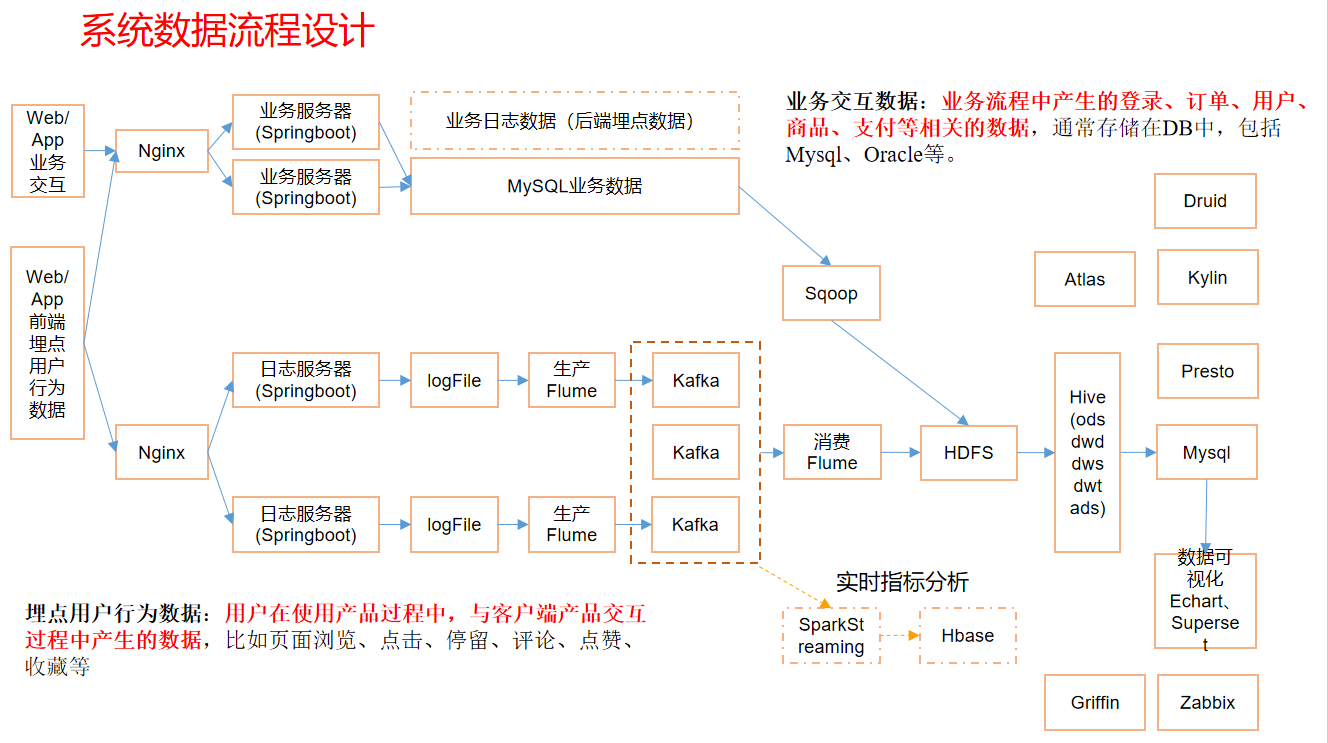
日志数据采集平台
埋点用户行为数据的形式:
- 存储在文件中
- 分为启动日志数据(启动日志=公共字段+启动事件数据)和事件日志数据
埋点用户行为数据:(数据流动路径)
生产flume数据流向

生产flume
为什么用Kafka,基于磁盘,当数据峰值来临时可以消峰,暂时存储在Kafka中,防止太多数据涌入HDFS导致Hadoop 宕机。
采用TaiDirSource:支持断点续传,多目录。数据可能会重复,后续再处理
采用Kafka Channel:速度高于 MemoryChannel + KafkaSink
flume具体配置,flume配置文件一般命名成数据的走向形式,例如:file-flume-kafka.conf
flume 五步走:(具体配置查看官网的各个组件不同的案例)
- 定义Source,Channel, Sink组件
- 配置Source
- 配置Channel
- 配置Sink
- 配置三者之间的关系
配置拦截器
打包,然后放到flume/lib/目录下
ETL拦截器
- 过滤时间戳不合法和Json数据不完整的数据。
- 实现Interceptor接口,重写initialize(),intercept(),close()方法,实现一个静态内部类,返回定义的拦截器对象。intercept()重载了两个,分别表示单event处理,多event处理(多event处理一般只需要在里面调用单event处理就行了)
- 启动日志判断是否是以“{”开头“}”结尾
- 判断事件日志的格式:
- 1.是否是时间戳+logs,
- 2.时间戳是否是合法的时间戳:时间戳长度是否为13,NumberUtils.isDigits() :判断字符串中是否全为数字
- logs是否以“{” 开头,“}” 结尾
日志类型区分拦截器
- 主要是为了给ChannelSelector配置mutiplexing根据event头,将启动日志和事件日志分开,进入不同的KafkaTopic。
- 在intercept()方法中,getHeaders(),再根据body中的数据判断为启动日志还是事件日志,分别给头加上不同的标识,要与配置的flume 文件匹配。headers.put(“topic”,”topic_start”);headers.put(“topic”,”topic_event”);
生产flume配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34a1.sources=r1
a1.channels=c1 c2
# configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/flume/test/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.zt.flume.interceptor.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.zt.flume.interceptor.LogTypeInterceptor$Builder
#配置多路复用,根据header的不同去往不同的channel
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
# configure channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop100:9092,hadoop101:9092,hadoop102:9092
a1.channels.c1.kafka.topic = topic_start
#配置parseAsFlumeEvent为false,不让header信息传到Kafka中去,只传输body中的数据
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = hadoop100:9092,hadoop101:9092,hadoop102:9092
a1.channels.c2.kafka.topic = topic_event
a1.channels.c2.parseAsFlumeEvent = false
a1.channels.c2.kafka.consumer.group.id = flume-consumer- –conf/-c:表示配置文件存储来conf/目录
- –name/-n:表示给agent起名为a1
- –conf-file/-f:flume本次读取的配置文件
- -Dflume.root.logger=INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error。
- flume-ng agent –conf-file /opt/module/flume/conf/file-flume-kafka.conf –name a1 -Dflume.root.logger=INFO,LOGFILE
消费flume
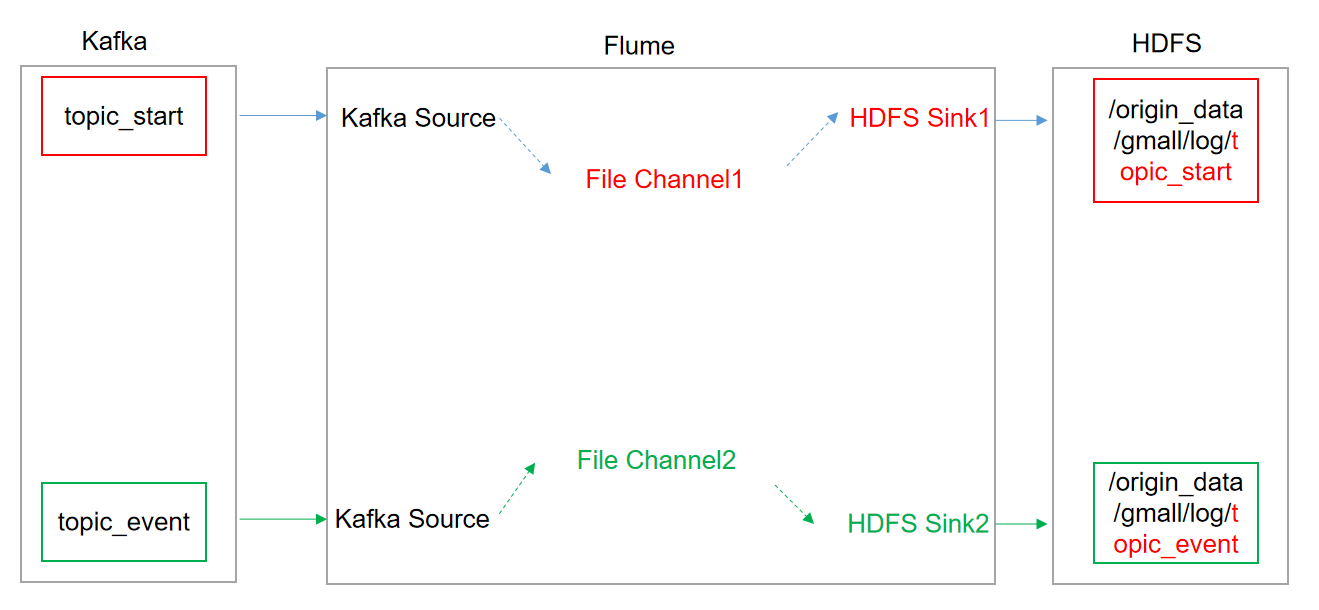
flume agent里面的组件更多的时候代表的是逻辑上的概念。比如两个KafkaChannel ,但是Kafka集群却可以有很多。
采用Kafka Source FileChannel HDFS Sink的方式传输数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68## 组件
a1.sources=r1 r2
a1.channels=c1 c2
a1.sinks=k1 k2
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
#一次传出event的条数
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop100:9092,hadoop101:9092,hadoop102:9092
a1.sources.r1.kafka.topics=topic_start
## source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.kafka.bootstrap.servers = hadoop100:9092,hadoop101:9092,hadoop102:9092
a1.sources.r2.kafka.topics=topic_event
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## channel2
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c2.dataDirs = /opt/module/flume/data/behavior2/
a1.channels.c2.maxFileSize = 2146435071
a1.channels.c2.capacity = 1000000
a1.channels.c2.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logstart-
##sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
## 不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
## 三者之间的关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2HDFS Sink产生小文件问题
a1.sinks.k1.hdfs.rollInterval = 10 多久生产一个新文件10s
a1.sinks.k1.hdfs.rollSize = 134217728 设置每个文件的滚动大小128M
a1.sinks.k1.hdfs.rollCount = 0 文件的滚动与Event数量无关 never roll based on number of events)
业务数据采集平台
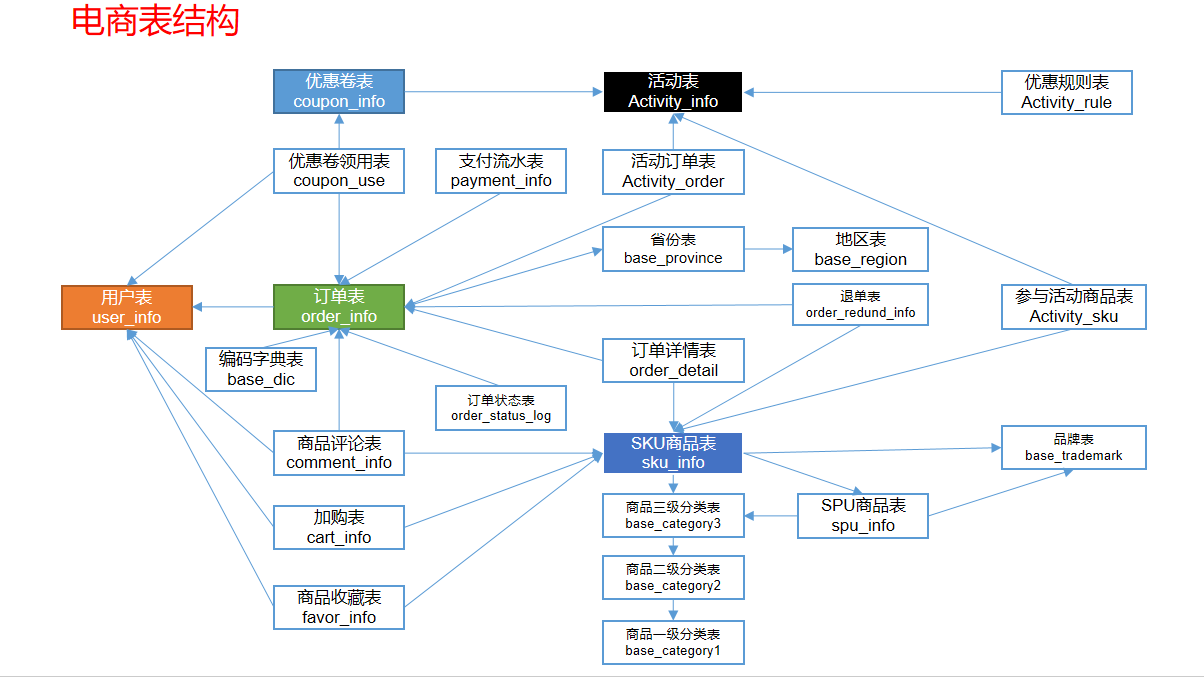
- 电商常识
- SKU(库存量基本单位),每种产品均对应有唯一的SKU号
- SPU(商品信息聚合的最小单位)
- iPhoneX手机就是SPU。一台银色、128G内存的、支持联通网络的iPhoneX,就是SKU。
- 电商业务表结构
同步策略
- 数据同步策略类型包括:全量同步策略,增量同步策略,新增及变化同步策略,特殊同步策略
- 全量表:存储完整的数据
- 每日全量,就是每天存储一份完整数据,作为一个分区
- 适用于表数据量不大,且每天会有新数据插入,也会有旧数据修改的场景
- 增量表:存储新增加的数据
- 每日增量,就是每天存储一份增量数据,作为一个分区
- 适用于表数据量大,且每天只会有新数据插入的场景
- 新增及变化表:存储新增加的数据和变化的数据
- 每日新增及变化,就是存储创建时间和操作时间都是今天的数据。
- 适用场景,表的数据量大,既会有新增,又会有变化
- 特殊表:只需要存储一次
- 某些特殊的维度表,可不必遵循上述同步策略
- 客观世界维度:没有变化的客观世界维度(性别,地区,名族,政治成分,鞋子尺码)可以只存一份固定值。
- 日期维度:日期维度可以一次性导入一年或若干年的数据
- 地区维度:省份表,地区表
业务数据导入HDFS
分析表同步策略
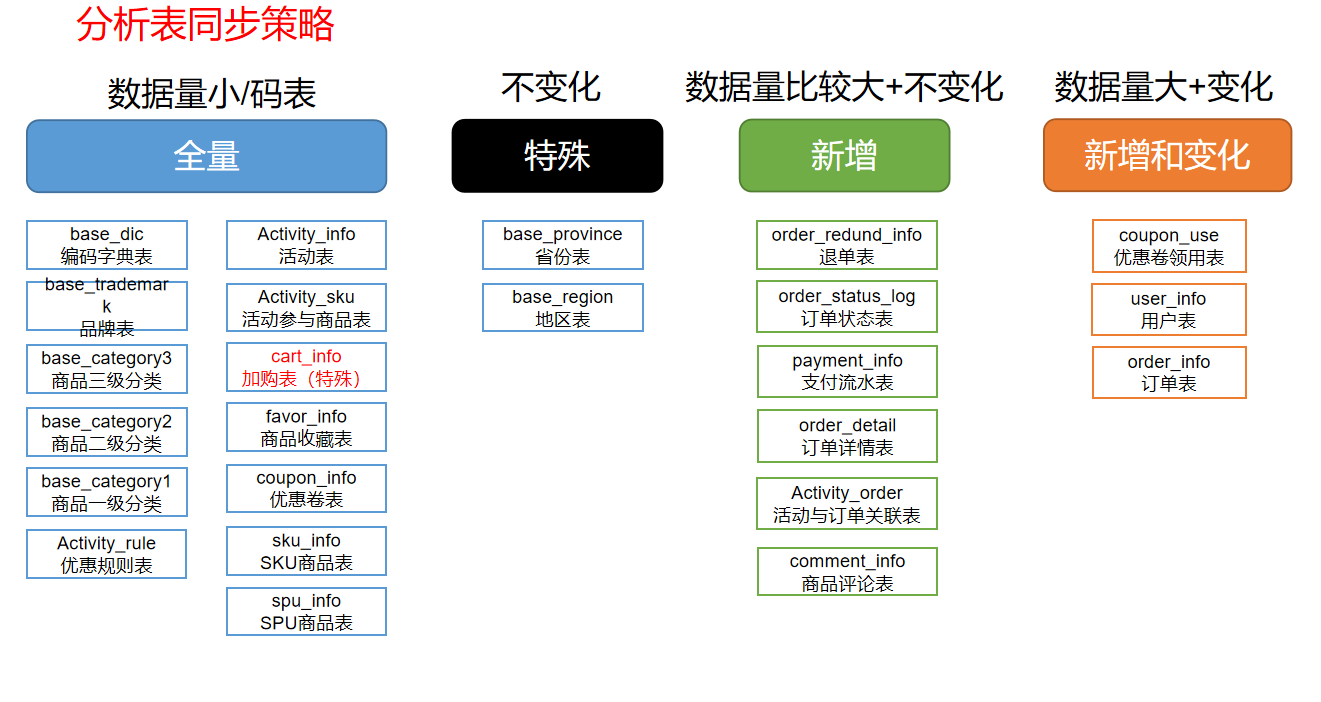
- 活动参与商品表没有放入ods层
- 根据不同的同步策略,编写脚本把数据导入到HDFS中去。采用sqoop将数据传入,采用LZO压缩
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!