flink
本文最后更新于:2024年12月11日 晚上
Flink
Flink简介
Apache Flink是为分布式,高性能,随时可用以及准确的流处理应用程序打造的开源流处理框架。
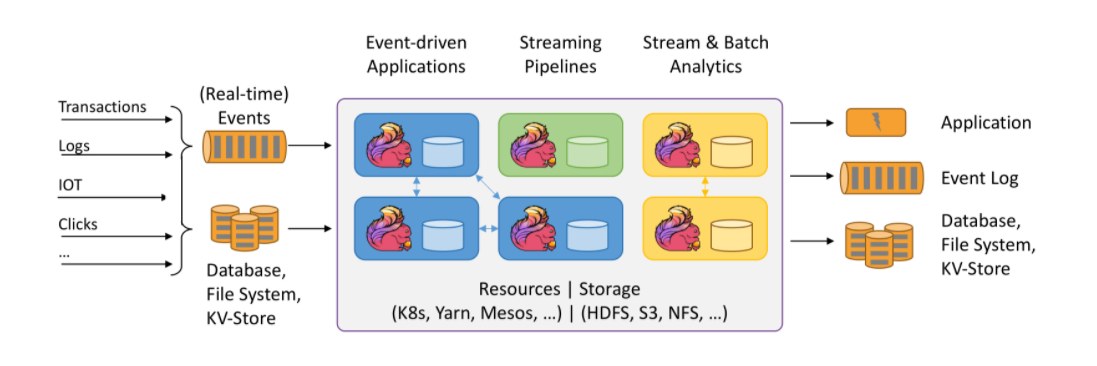
流处理架构的演变
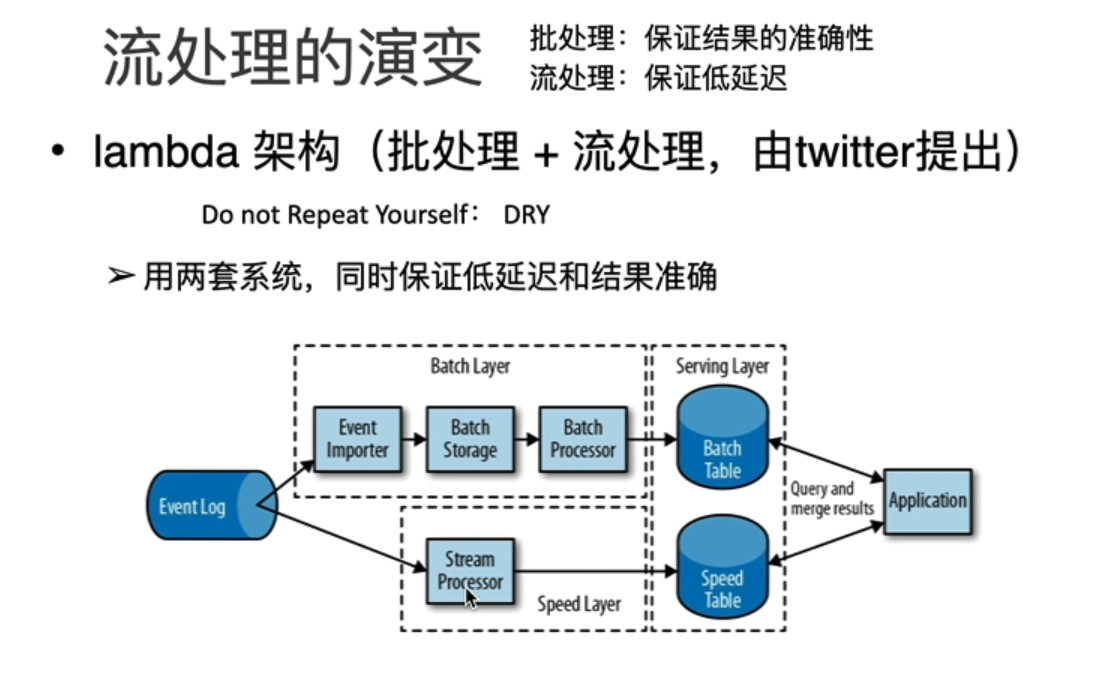
- lambda 架构(批处理+流处理 ,由twitter提出)
- flink 流批统一(同时保证低延迟和结果正确)
- lambda 架构(批处理+流处理 ,由twitter提出)
特点
Flink的重要特点:
- 事件型驱动(Event-driven)事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算,状态更新或其他外部动作。比较典型的就是以Kafka为代表的消息队列几乎都是事件驱动型应用。
与Spark对比:
- 在spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个个无限的小批次组成的,最本质上来说还是批处理的。
- 在Flink的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
分层API
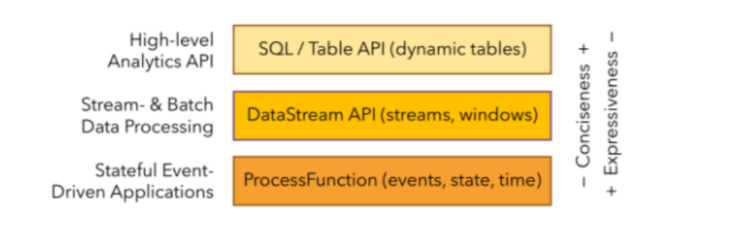
- 最底层的抽象仅仅提供了有状态流,它将通过过程函数(Process Function)被嵌入到DataStream API中,底层过程函数(Process Function)与DataStream API相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。
- 目前Flink作为批处理还不是主流,不如Spark成熟,所以DataSet使用的并不是很多。Flink Table API和Flink SQL也并不完善,大多都由各大厂商自己定制。所以我们主要学习DataStream API的使用。实际上Flink作为最接近Google DataFlow模型的实现,是流批统一的观点,所以基本上使用DataStream就可以了。
快速上手
搭建maven工程,添加Scala框架
参考pom文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.zt.flink</groupId>
<artifactId>Flink</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
批处理wordcount。记得导包:import org.apache.flink.api.scala._ 否则会报错no implicits found for parameter evidence
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import org.apache.flink.api.scala._
object PiChuLiWordCount {
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 从文件中读取数据
val inputPath = "E:\\idea\\flink\\src\\main\\Scala\\word.txt"
val inputDS: DataSet[String] = env.readTextFile(inputPath)
// 分词之后,对单词进行groupby分组,然后用sum进行聚合
val wordCountDS: AggregateDataSet[(String, Int)] =
inputDS.flatMap(_.split(" "))
.map((_,1))
.groupBy(0)
.sum(1)
// 打印输出
wordCountDS.print()
}
}流处理的wordcount
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import org.apache.flink.streaming.api.scala._
object StreamWordCount {
def main(args: Array[String]): Unit = {
//创建流处理环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//接收socket 文本流
val textDstream: DataStream[String] = env.socketTextStream("hadoop100", 7777)
import org.apache.flink.api.scala._
val dataStream: DataStream[(String, Int)] = textDstream.flatMap(_.split("\\s"))
.filter(_.nonEmpty)
.map((_, 1))
.keyBy(0)
.sum(1)
dataStream.print().setParallelism(1);
//启动excutor ,执行任务
env.execute("Socket stream word count")
}
}
Flink部署
- standalone模式
- 解压缩,修改flink/conf/flink-conf.yaml文件,jobmanager.rpc.address:hadoop100
- 修改flink/conf/slaves文件 加上从机器的机器名hadoop101,hadoop102
- 分发flink文件
- Yarn模式
- Session-Cluster
- Per-Job-Cluster
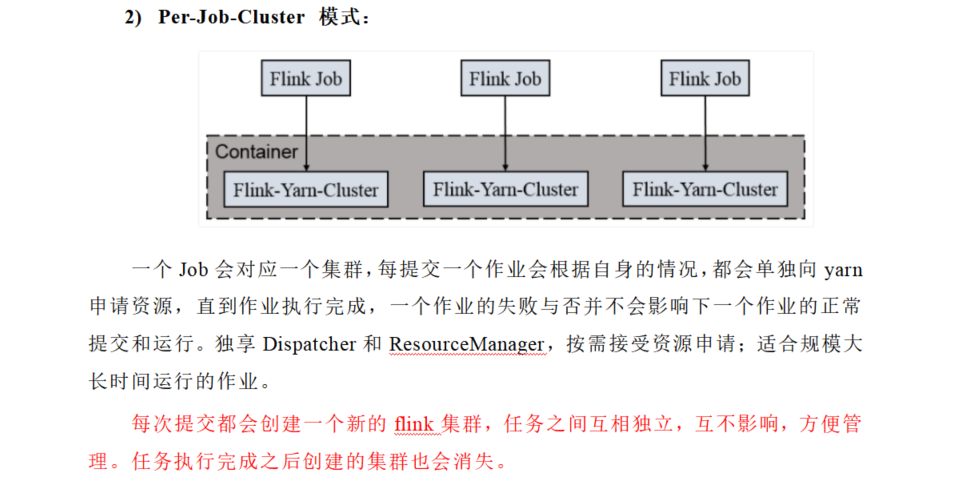
- Per-job模式在Flink1.15中已经被弃用
- application模式
- flink-1.11 引入了一种新的部署模式,即 Application 模式。目前,flink-1.11 已经可以支持基于 Yarn 和 Kubernetes 的 Application 模式。
- Session模式:所有作业共享集群资源,隔离性差,JM 负载瓶颈,main 方法在客户端执行。
- Per-Job模式:每个作业单独启动集群,隔离性好,JM 负载均衡,main 方法在客户端执行。
- 缺点:
- 1.main方法都在客户端执行,在客户端执行 main() 方法来获取 flink 运行时所需的依赖项,并生成 JobGraph,提交到集群的操作都会在实时平台所在的机器上执行,那么将会给服务器造成很大的压力。尤其在大量用户共享客户端时,问题更加突出。
- 2.提交任务时会把本地flink的所有jar包先上传到hdfs上相应的临时目录,这个也会带来大量的网络开销,如果任务特别多的情况下,平台的吞吐量将会直线下降。
- Application 模式下,用户程序的 main 方法将在集群中而不是客户端运行,用户将程序逻辑和依赖打包进一个可执行的 jar 包里,集群的入口程序 (ApplicationClusterEntryPoint) 负责调用其中的 main 方法来生成 JobGraph。
- Yarn Application 与Per-Job 模式类似,只是提交任务不需要客户端进行提交,直接由JobManager来进行任务提交,每个Flink Application对应一个Flink集群,如果该Flink Application有多个job任务,所有job任务共享该集群资源,TaskManager也是根据提交的Application所需资源情况动态进行申请。
- Session-Cluster
- Kubernetes部署
- 容器化部署是是目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。现在最流行地就是K8s了,flink也支持k8s部署模式
运行架构(重点)
运行时的组件
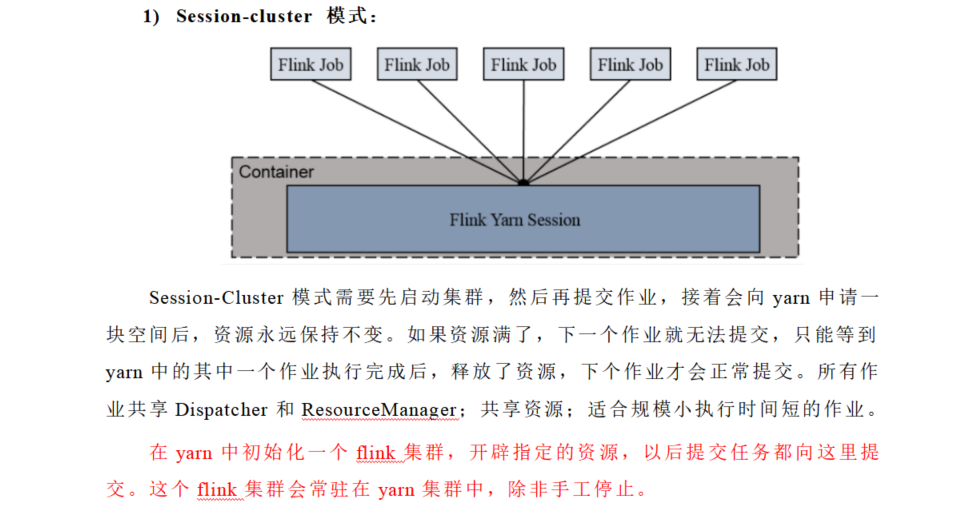
- Flink运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:作业管理器(JobManager),资源管理器(ResourceManager),任务管理器(TaskManager),以及分发器(Dispatcher)。Flink是由Java和Scala实现的,因此所有的组件都会运行在Java虚拟机中。
- 作业管理器(JobManager)
- 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager 所控制执行。JobManager会先接收到要执行的应用程序,这个应用程序包括:作业图(JobGraph),逻辑数据流图(logical dataflow graph)和打包了所有的类,库和其他资源的JAR包。JobManager会把作业图转换成一个物理层面的数据流图,这个图被叫做”执行图“(ExecutionGraph),包含了所有可以并发执行的任务。作业管理器会向资源管理器请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦作业管理器获取到了足够的资源,就会将执行图分发到真正运行他们的任务管理器(TaskManager)上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如检查点(checkpoint)的协调。
- 资源管理器(ResourceManager)
- 主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManager插槽是Flink中定义的处理资源单位。Flink为不同的环境和资源管理工具提供了不同的资源管理器,比如Yarn,K8s,standalone。当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager 。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器,另外,ResourceManager还负责终止空闲的TaskManager,释放计算资源。
- 任务管理器(TaskManager)
- 通常一个Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能执行的任务数量。任务管理器启动之后会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给任务管理器(JobManager)调用。任务管理器就可以向插槽分配任务(tasks)来执行。在执行过程中,一个任务管理器可以跟其它运行同一应用程序的TaskManager交换数据。
- 分发器(Dispatcher)
- 可以跨作业运行,它为应用提交提供了REST接口。当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。由于是REST接口,所以Dispatcher可以作为集群的一个HTTP接入点,这样就能够不受防火墙阻挡。Dispatcher也会启动一个Web UI,用来方便的展示和监控作业执行的信息。Dispatcher 在架构中可能并不是必须的,这取决于应用提交运行的方式。
- REST接口:REST 用来规范应用如何在 HTTP 层与 API 提供方进行数据交互 。REST 描述了 HTTP 层里客户端和服务器端的数据交互规则;客户端通过向服务器端发送 HTTP(s)请求,接收服务器的响应,完成一次 HTTP 交互。这个交互过程中,REST 架构约定两个重要方面就是 HTTP 请求所采用的方法,以及请求的链接。
任务提交流程
- Yarn环境下任务的提交流程
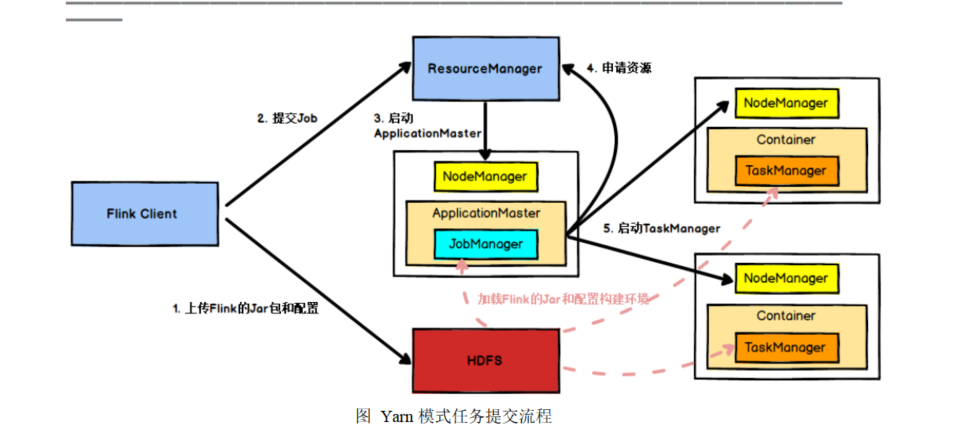
- Client向HDFS上传Flink的Jar包和配置
- Client向ResourceManager提交任务
- ResourceManager分配Container资源并通知对应的NodeManager启动ApplicationMaster
- ApplicationMaster启动后下载Client提交的资源和配置构建环境,启动JobManager
- ApplicationMaster向ResourceManager申请Container资源启动TaskManager。(NodeManager加载flink的jar包和配置构建环境并启动TaskManager)
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务
任务调度原理
客户端(Client)不是运行时和程序执行的一部分,但它用于准备并发送dataflow(JobGraph)给Master(JobManager),然后,客户端断开连接或者维持连接以等待接收计算结果。
Client,JobManager,TaskManager三者均为独立的JVM进程。
TaskManager与Slots
- TaskManager是一个JVM进程,它可能会在独立的线程上执行一个或多个subtask。为了控制一个TaskManager能接收多少个task,Task Manager通过task slot来进行控制。(一个Task Manager至少有一个task slot)
- 每一个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么他会将其管理的内存分成三份给各个slot。
- 一个TaskManager多个slot意味着更多的subtask可以共享一个JVM。
- Task Slot是静态的概念,是指TaskManager具有的并发执行的能力,可以通过参数配置,而并行度parallelism是动态概念,即TaskManager运行程序时实际使用的并发能力。可以通过参数配置
程序与数据流
所有flink都是由三部分组成的
Source
- 负责读取数据源
Transformation
- 利用各种算子进行处理加工
Sink
- 负责进行输出
在运行时,Flink 上运行的程序会被映射成”逻辑数据流“(dataflows),它包含了这三部分,每一个dataflow以一个或多个source开始以一个或多个sinks结束dataflow类似于任意的有向无环图(DAG)
执行图
- 由Flink程序直接映射成的数据流图是StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(也叫执行图),详细说明程序的执行方式。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
并行度
在flink程序执行过程中,一个流(stream)包含一个或多个分区(stream partition),而每个算子(operator)可以包含一个或多个子任务(operator subtask)
一个特定算子的子任务(subtask)的个数称作它的并行度
stream算子之间传输数据的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式
One-to-one:stream(比如在source和map operator之间)维护着分区以及元素的顺序。那意味着map 算子的子任务看到的元素的个数以及顺序跟source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap等算子都是one-to-one的对应关系。类似于spark中的窄依赖
Redistributing:stream(map()跟keyBy/window之间或者keyBy/window跟sink之间)的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如,keyBy() 基于hashCode重分区、broadcast和rebalance会随机重新分区,这些算子都会引起redistribute过程,而redistribute过程就类似于Spark中的shuffle过程。类似于spark中的宽依赖。
任务链
- 相同并行度的one to one操作,Flink这样相连的算子链接在一起形成一个task,原来的算子成为里面的一部分。将算子链接成task是非常有效的优化,它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
Flink 流处理API
Environment
- ExcutionEnvironment.getExcutionEnvironment
- val env = StreamExecutionEnvironment.createLocalEnvironment(1)
- val env = ExecutionEnvironment.createRemoteEnvironment(“jobmanage-hostname”, 6123,”YOURPATH//wordcount.jar”)
Source
- 从集合读取数据
- 从文件读取数据
- 以Kafka消息队列的数据作为来源
- 自定义Source
Transform
- map
- flatMap
- Filter
- KeyBy
- 滚动聚合算子
- Reduce
- Split和Select
- Connect和CoMap
- Union
支持的数据类型
- 基础数据类型
- Java和Scala元组
- Scala样例类
- Java简单对象
- Flink对Java和Scala中的一些特殊目的的类型也都是支持的,比如Java的ArrayList,HashMap,Enum等等。
实现UDF函数
- 函数类(Function Classes)
- 匿名函数(Lambda Functions)
- 富函数(Rich Functions)
- 富函数是DataStream API提供的一个函数类接口,所有Flink函数类都有其Rich版本
- 富函数与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
Sink
- Kafka
- Redis
- Elasticsearch
- JDBC自定义sink
Flink中的Window(重点)
flink中处理一般是分流–》开窗–》聚合
窗口就是将无限流切割成为有限流的一种方式,它会将流数据分发到有限大小的桶中进行分析
窗口类型:时间窗口,计数窗口
时间窗口
- 滚动时间窗口
- 滑动时间窗口
- 会话窗口(flink支持)
计数窗口
- 滚动计数窗口
- 滑动计数窗口
增量聚合函数 AggregateFunction
- 来一条数据进行一次运算,只保存一个简单的状态(累加器)
- 当窗口闭合的时候,增量聚合完成
- 处理时间:当机器时间超过窗口结束时间的时候,窗口闭合
- 来一条数据计算一次
全窗口聚合函数 ProcessWindowFunction
- 先把窗口所有的数据收集起来,等到计算的时候会遍历所有数据
- 可以访问到窗口信息
可以将增量窗口聚合函数和全窗口聚合函数结合使用,ProcessWindowFunction提供更多对数据流的访问权限(比如窗口开始时间,窗口结束时间),但是耗性能,先用AggregateFunction处理,最后传一个结果值给ProcessWindowFunction。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
//最低最高温度
object MinMaxTemp {
//样例类
case class MinMaxTemp(id: String, min: Double, max: Double, endTs: Long)
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[SensorReading] = env.addSource(new SensorSource)
stream.keyBy(_.id).timeWindow(Time.seconds(5))
.aggregate(new HighAndLowAgg, new WindowResult)
.print()
env.execute()
}
//增量聚合函数
class HighAndLowAgg extends AggregateFunction[SensorReading, (String, Double, Double), (String, Double, Double)] {
override def createAccumulator(): (String, Double, Double) = ("", Double.MaxValue, Double.MinValue)
override def add(value: SensorReading, accumulator: (String, Double, Double)): (String, Double, Double) =
(value.id, value.temperature.min(accumulator._2), value.temperature.max(accumulator._3))
override def getResult(accumulator: (String, Double, Double)): (String, Double, Double) = accumulator
override def merge(a: (String, Double, Double), b: (String, Double, Double)): (String, Double, Double) =
(a._1, a._2.min(b._2), a._3.max(b._3))
}
//全窗口聚合函数
class WindowResult extends ProcessWindowFunction[(String, Double, Double), MinMaxTemp, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Double, Double)], out: Collector[MinMaxTemp]): Unit = {
val minMax: (String, Double, Double) = elements.head
out.collect(MinMaxTemp(key, minMax._2, minMax._3, context.window.getEnd))
}
}
}
Flink中的时间语义和Watermark(重点)
时间语义
- 事件时间(event time)
- 真正正确的时间,时间语义完全正确。事件创建的事件(必须包含在数据源中的元素里面)
- 是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
- flink事件事件单位是ms,代码中需要注意
- 机器时间
- Ingestion Time(摄入时间) :数据进入Flink的时间,与机器相关
- Processing Time(处理时间): 是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time
Watermark
- 当Flink以Event Time模式处理数据流时,它会根据数据里的时间戳来处理基于时间的算子
- 由于网络,分布式等原因,会导致乱序数据的产生
- 乱序数据会让窗口计算不准确
- 窗口的区间是左闭右开区间
- Watermark的特点
- 水位线:系统认为时间戳小于水位线的事件都已经达到了
- 水位线是一种特殊的事件,在source算子后面插入到流中
- 事件时间窗口的闭合触发规则:水位线大于等于窗口结束时间的时候
- 水位线由程序员编程插入到流中,水位线是一个特殊的事件
- 水位线几个重要的概念
- Flink默认每隔200ms(机器时间)向数据流中插入一次Watermark
- 水位线产生的公式:水位线=系统观察到的最大事件时间 - 最大延迟时间
- 最大延迟时间由程序员自己设定
- 分配时间戳和水位线一定要在keyBy之前进行
- 为了保证事件时间的正确性:Flink有三重保障
- watermark
- 允许迟到时间 allowedLateness()
- 侧输出流 sideOutputLateData()
ProcessFunction API(底层 API)
之前学习的转换算子是无法访问事件的时间戳信息和水位线信息的。基于此 DataStream API提供了一系列的Low-Level转换算子。可以访问时间戳,watermark以及注册定时事件。还可以输出特定的一些事件,例如超时事件等。ProcessFunction用来构建事件驱动的应用以及实现自定义的业务逻辑(使用之前的window 函数和转换算子无法实现)。例如,Flink SQL就是使用Process Function实现的。
常用的几个
- KeyedProcessFunction:KeyBy以后的流,没有开窗口
- ProcessFunction:既没有分流也没有开窗
- ProcessWindowFunction:分流和开窗口以后的流
- ProcessAllWindowFunction:没有分流,但是开了窗口的流
- CoProcessFunction:两条联合的流(connect)
- AggregateFunction:窗口的增量聚合函数
- Trigger: 窗口聚合函数的底层实现,可以自由的控制窗口计算的时机
常用函数的案例:
KeyedProcessFunction
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
//检查连续1s内温度上升
object TempIncreaseAlert {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
.keyBy(_.id)
.process(new TempIncreaseAlertFunction)
stream.print()
env.execute()
}
class TempIncreaseAlertFunction extends KeyedProcessFunction[String, SensorReading, String] {
//初始化一个状态变量
//懒加载,惰性赋值
//当执行到process算子时,才会初始化,所以是懒加载
//通过配置,状态变量可以通过检查点操作,保存在hdfs里面
//当程序故障时,可以从最近一次检查点恢复
//所以要有一个名字last-temp和变量的类型(需要明确告诉flink状态变量的类型)
//状态变量只会被初始化一次,允许程序时,如果没有这个状态变量,就初始化一个,如果有这个状态变量,直接读取,是单例模式
lazy val lastTemp = getRuntimeContext.getState(
new ValueStateDescriptor[Double]("last-temp", Types.of[Double])
)
//用来保存报警定时器的时间戳,默认是0L
lazy val timerTs = getRuntimeContext.getState(
new ValueStateDescriptor[Long]("ts", Types.of[Long])
)
override def processElement(value: SensorReading, ctx: KeyedProcessFunction[String, SensorReading, String]#Context, out: Collector[String]): Unit = {
//获取最近一次温度,调用'.valeu()'方法
//如果来的是第一条温度,那么prevTemp是0.0
val prevTemp = lastTemp.value()
//将来的温度值更新到lastTemp状态变量,使用update方法
lastTemp.update(value.temperature)
val curTimerTs = timerTs.value()
if (prevTemp == 0.0 || value.temperature < prevTemp) {
//如果来的温度是第一条温度,或者来的温度小于最近一次温度
//删除报警定时器
ctx.timerService().deleteProcessingTimeTimer(curTimerTs)
//情况保存定时器时间戳的状态变量,使用clear方法
timerTs.clear()
} else if (value.temperature > prevTemp && curTimerTs == 0L) {
//来的温度大于最近一次温度,并且我们没有注册报警定时器,因为curTimerTs等于0L
val ts = ctx.timerService().currentProcessingTime() + 1000L
ctx.timerService().registerProcessingTimeTimer(ts)
timerTs.update(ts)
}
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, SensorReading, String]#OnTimerContext, out: Collector[String]): Unit = {
out.collect("传感器ID为" + ctx.getCurrentKey + "的传感器温度连续1s上升")
timerTs.clear() //清空定时器
}
}
}ProcessFunction
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object FreezingAlarm {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
//没有KeyBy,没有开窗口函数
.process(new FreezingAlarmFunction)
//stream.print()//打印常规输出
//打印侧输出流
//侧输出标签的名字必须是一样的
stream.getSideOutput(new OutputTag[String]("freezing-alarm")).print()
env.execute()
}
//ProcessFunction处理的是没有KeyBy的流
class FreezingAlarmFunction extends ProcessFunction[SensorReading, SensorReading] {
//定义一个侧输出标签,实际上就是侧输出流的名字
//侧输出流中的元素泛型是String
lazy val freezingAlarmOut = new OutputTag[String]("freezing-alarm")
override def processElement(value: SensorReading, ctx: ProcessFunction[SensorReading, SensorReading]#Context, out: Collector[SensorReading]): Unit = {
if (value.temperature < 32.0) {
//第一个参数是侧输出标签,第二个参数是发送的数据
ctx.output(freezingAlarmOut, value.id + "的传感器低温报警")
}
//将所以读数发送到常规输出
out.collect(value)
}
}
}CoProcessFunction
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.functions.co.CoProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object CoProcessFunctionExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//第一条流,无限流
val stream1 = env.addSource(new SensorSource)
//第二条流,有限流,只有一个元素,用来做开关,对Sensor_7的数据放行10s
val stream2 = env.fromElements(
("Sensor_7", 5 * 1000L)
)
val result = stream1
.connect(stream2)
.keyBy(_.id, _._1) //on stream1.id=stream2._1
.process(new ReadingFilter)
result.print()
env.execute()
}
class ReadingFilter extends CoProcessFunction[SensorReading, (String, Long), SensorReading] {
//初始值为false
lazy val forwardEnabled = getRuntimeContext.getState(
new ValueStateDescriptor[Boolean]("switch", Types.of[Boolean])
)
//处理来自传感器的流数据
override def processElement1(value: SensorReading, ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#Context, out: Collector[SensorReading]): Unit = {
//如果开关为true,就允许数据流向下发送
if (forwardEnabled.value()) {
out.collect(value)
}
}
//处理来自开关流的数据
override def processElement2(value: (String, Long), ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#Context, out: Collector[SensorReading]): Unit = {
//打开开关
forwardEnabled.update(true)
//开关元组的第二个值是放行时间
val ts = ctx.timerService().currentProcessingTime() + value._2
//注册一个定时器
ctx.timerService().registerProcessingTimeTimer(ts)
}
override def onTimer(timestamp: Long, ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#OnTimerContext, out: Collector[SensorReading]): Unit = {
//关闭开关
forwardEnabled.clear()
}
}
}
水位线+迟到事件处理+侧输出流处理
- 每200ms系统默认插入一个水位线
- 窗口是一个左闭右开的区间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object UpdateWindowResultWithLateElement {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//设置事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val stream = env
.socketTextStream("hadoop100", 9999, '\n')
.map(line => {
val arr = line.split(" ")
(arr(0), arr(1).toLong * 1000L)
})
.assignTimestampsAndWatermarks(
//最大延迟时间5s
new BoundedOutOfOrdernessTimestampExtractor[(String, Long)](Time.seconds(5)) {
override def extractTimestamp(element: (String, Long)): Long = element._2
}
)
.keyBy(_._1)
.timeWindow(Time.seconds(5))
//允许迟到时间
.allowedLateness(Time.seconds(5))
//将迟到事件发送到侧输出流中去
.process(new UpdateWindowResult)
stream.print()
env.execute()
}
class UpdateWindowResult extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
//当第一次对窗口进行求值时,也就是水位线超过窗口结束时间的时候
//会第一次调用process函数
//这是isUpdate为默认值false
//窗口内初始化一个状态变量使用windowState,只对当前窗口可见
val isUpdate = context.windowState.getState(
new ValueStateDescriptor[Boolean]("update", Types.of[Boolean])
)
if (!isUpdate.value()) {
//当水位线超过窗口结束时间,第一次调用
out.collect("窗口第一次求值了!元素共有" + elements.size + " 个")
//第一次调用完process后,将isUpdate赋值为true
isUpdate.update(true)
} else {
out.collect("迟到元素来了,更新的元素数量为" + elements.size + " 个")
}
}
}
}触发器Trigger
每次调用Trigger都会产生一个TriggerResult来决定窗口接下来发生什么。TriggerResult可以取以下结果:
- CONTINUE:什么都不做
- FIRE:如果window operator有ProcessWindowFunction这个参数,将会调用ProcessWindowFunction,如果窗口仅有增量聚合函数(ReduceFunction或者AggregateFunction)作为参数,那么当前的聚合结果将会被发送,窗口的state不变
- PURGE:窗口所以内容包括窗口的元数据都将被丢弃
- FIRE_AND_PURGE:先对窗口求值,再将窗口中的内容丢弃
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.triggers.Trigger.TriggerContext
import org.apache.flink.streaming.api.windowing.triggers.{Trigger, TriggerResult}
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object TriggerExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val stream = env
.socketTextStream("hadoop100", 9999, '\n')
.map(line => {
val arr = line.split(" ")
(arr(0), arr(1).toLong)
})
.assignAscendingTimestamps(_._2)
.keyBy(_._1)
.timeWindow(Time.seconds(10))
.trigger(new OneSecondIntervalTrigger)
.process(new WindowCount)
stream.print()
env.execute()
}
class OneSecondIntervalTrigger extends Trigger[(String, Long), TimeWindow] {
//每来一条元素都要调用一次
override def onElement(element: (String, Long), timestamp: Long, window: TimeWindow, ctx: TriggerContext): TriggerResult = {
//默认值为false
//当第一条事件来的时候将firstSeen置为false
val firstSeen = ctx.getPartitionedState(
new ValueStateDescriptor[Boolean]("first-seen", Types.of[Boolean])
)
//当第一条数据来的时候,!firstSeen.value()为true
//仅对第一条数据注册定时器
//这里的定时器指的是:onEventTime函数
if (!firstSeen.value()) {
//如果当前水位线为1234,那么t=1234+(1000-1234%1000)=2000
println("第一条数据进入时的水位线是:"+ctx.getCurrentWatermark)
val t = ctx.getCurrentWatermark + (1000 - (ctx.getCurrentWatermark % 1000))
println("第一次注册的定时器时间是:"+ t)
ctx.registerEventTimeTimer(t) //第一条数据的时间戳之后的整数秒注册一个定时器
println("第一次注册的窗口结束时间定时器时间是:"+window.getEnd)
ctx.registerEventTimeTimer(window.getEnd) //在窗口结束时间注册一个定时器
firstSeen.update(true)
}
TriggerResult.CONTINUE //什么都不敢(fire=false,purge=false)
}
//我们使用的是事件事件,所以onProcessingTime什么都不用做
override def onProcessingTime(time: Long, window: TimeWindow, ctx: TriggerContext): TriggerResult = {
TriggerResult.CONTINUE
}
//定时器函数,在水位线到达time时触发
override def onEventTime(time: Long, window: TimeWindow, ctx: TriggerContext): TriggerResult = {
println("当前水位线是"+ctx.getCurrentWatermark)
//在onElement函数中,我们注册过窗口结束时间的定时器
if (time == window.getEnd) {
//在窗口闭合时,触发计算并清空窗口
TriggerResult.FIRE_AND_PURGE
} else {
val t = ctx.getCurrentWatermark + (1000 - (ctx.getCurrentWatermark % 1000))
if (t < window.getEnd) {
ctx.registerEventTimeTimer(t)
println("注册的定时器时间是:"+t)
}
TriggerResult.FIRE
}
}
override def clear(window: TimeWindow, ctx: TriggerContext): Unit = {
//状态变量是一个单例
val firstSeen = ctx.getPartitionedState(
new ValueStateDescriptor[Boolean]("first-seen", Types.of[Boolean])
)
firstSeen.clear()
}
}
class WindowCount extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
out.collect("窗口中有" + elements.size + "条数据! " + "窗口结束时间是" + context.window.getEnd)
}
}
}
Flink状态编程和容错机制
状态编程
流式计算分为无状态编程和有状态编程两种情况。无状态计算观察每个独立事件,并根据最后一个事件输出结果。
无状态计算例子:
- 流处理应用程序从传感器接收温度读数,并在温度超过90度时发出警告。
有状态计算例子:
- 所有窗口类型,例如,计算过去一小时的平均温度,就是有状态的计算
- 所有用于复杂事件处理的状态机。例如,若在一分钟内收到两个相差20度以上的温度读数,则发出警告,这就是有状态的计算。
- 流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作,都是有状态的计算。
可以认为状态就是一个本地变量,可以被任务的业务逻辑访问
无状态流处理每次只转换一条输入记录,并且仅根据最新的输入记录输出结果,有状态流处理维护所有已经处理记录的状态值,并根据每条新输入的记录更新状态,因此输出记录反映的是综合考虑多个事件之后的结果。
在Flink中,状态始终与特定算子相关联。总的来说,有两种类型的状态:
- 算子状态(operator state)
- 算子状态的作用范围限定为算子任务。这意味着同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的,算子状态不能由相同或不同算子的另一个任务访问。
- 键控状态 (keyed state)
- 键控状态是根据输入数据流中定义的键(key)来维护和访问的。Fink为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key的所有数据都会访问相同的状态。Keyed State很类似于一个分布式的key-value map数据结构,只能用于KeyedStream (KeyBy算子处理之后)
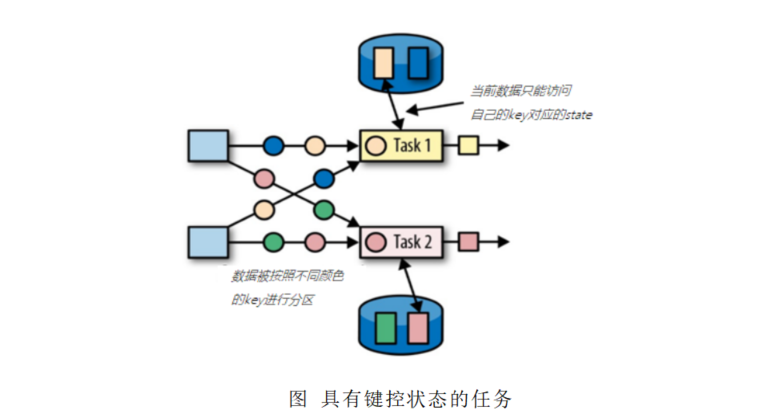
- Flink的Keyed State 支持以下数据类型:
- ValueState[T]保存单个的值,值的类型为T。
- get操作: ValueState.value()
- set操作: ValueState.update(value: T)
- ListState[T]保存一个列表,列表里的元素的数据类型为T。基本操作如下:
- o ListState.add(value: T)
- ListState.addAll(values: java.util.List[T])
- ListState.get()返回Iterable[T]
- ListState.update(values: java.util.List[T])
- MapState[K,V]保存Key-Value对
- MapState.get(key:K)
- MapState.put(key:K,value:V)
- MapState.contains(key:K)
- MapState.remove(key:K)
- ReducingState[T]
- AggregatingState[I,O]
- State.clear()是清空操作
- ValueState[T]保存单个的值,值的类型为T。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55import org.apache.flink.api.common.state.{ListStateDescriptor, ValueStateDescriptor}
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
import scala.collection.mutable.ListBuffer
object ListStateExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env
.addSource(new SensorSource)
.filter(_.id.equals("Sensor_1"))
.keyBy(_.id)
.process(new Keyed)
stream.print()
env.execute()
}
class Keyed extends KeyedProcessFunction[String, SensorReading, String] {
lazy val listState = getRuntimeContext.getListState(
new ListStateDescriptor[SensorReading]("list-state", Types.of[SensorReading])
)
lazy val timer = getRuntimeContext.getState(
new ValueStateDescriptor[Long]("timer", Types.of[Long])
)
override def processElement(value: SensorReading, ctx: KeyedProcessFunction[String, SensorReading, String]#Context, out: Collector[String]): Unit = {
listState.add(value) //添加value到列表状态变量中
if (timer.value() == 0L) {
val ts = ctx.timerService().currentProcessingTime() + 10 * 1000L
ctx.timerService().registerProcessingTimeTimer(ts)
timer.update(ts)
}
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, SensorReading, String]#OnTimerContext, out: Collector[String]): Unit = {
//不能直接对列表状态变量进行计数
val readings: ListBuffer[SensorReading] = new ListBuffer()
//隐式类型转换必须导入
import scala.collection.JavaConversions._
for (r <- listState.get()) {
readings += r;
}
out.collect("当前时刻列表状态变量里面共有" + readings.size + "条数据")
timer.clear() //清空定时器
}
}
}- 算子状态(operator state)
状态后端(State Backends)
- 每传入一条数据,有状态的算子任务都会读取和更新状态
- 由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会在本地维护其状态,以确保快速的状态访问。
- 状态的存储,访问以及维护,由一个可插入的组件决定这个组件就叫做状态后端。
- 状态后端主要负责两件事情,本地状态管理,以及将检查点(checkpoint)状态写入远程存储(HDFS)。
状态后端的选择
- MemoryStateBackend
- 内存级的状态后端,会将键控状态作为内存中的对象进行管理,将他们存储在TaskManager的JVM堆上,而将checkpoint存储在JobManager的内存中
- 特定:快速,但不稳定,一般用于测试
- FsStateBackend
- 将checkpoint存到远程的持久化文件系统(FileSystem)上,而对于本地状态,跟MemoryStateBackend一样,也会存储在TaskManager的JVM堆上
- 特点:同时拥有内存级的本地访问速度,和更好的容错保证
- RocksDBStateBackend
- 将所有状态序列化后,存入本地的RocksDB中存储。
- MemoryStateBackend
Flink的一个重大价值在于,它既保证了exactly-once,也具有低延迟和高吞吐的处理能力
容错机制
- Flink故障恢复机制的核心就是应用状态的一致性检查点
- 有状态应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候。
- 从检查点恢复状态过程:
- 遇到故障之后,第一步就是重启应用
- 第二步是从checkpoint中读取状态,将状态重置,从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同。
- 第三步:开始消费并处理检查点到发生故障之间的所有数据
- 这种检查点的保存和恢复机制可以为应用程序提供“精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流都会被重置到检查点完成时的位置。
- 保存点:flink提供了可以自定义的镜像保存功能,就是保存点(savepoints)
- 原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点
- flink不会自动创建保存点,需要用户手动执行的(在程序中编写相应的代码)
状态一致性
状态一致性级别
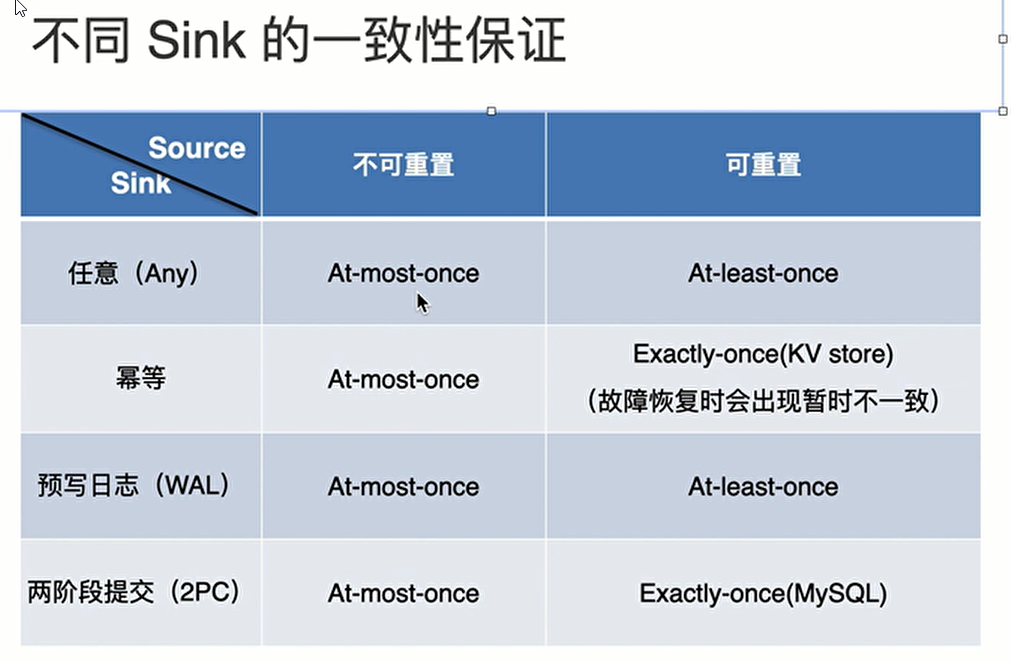
flink 端到端(end-to-end)状态一致性
内部保证 checkpoint
source端 可重设数据的读取位置 (Kafka,FileSystem)
sink 端 从故障恢复时,数据不会重复写入外部系统
幂等写入: 幂等操作就是指:一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了
事物写入: 具有原子性,一个事务中的一系列操作要么全部成功,要么一个都不做
- 实现思想:构建的事务对应着checkpoint,等到checkpoint 真正完成的时候,才把所有对应的结果写入sink系统中
- 实现方式:
- 预写日志 (宕机会导致不能实现exactly-once)
- 两阶段提交(真正实现exactly-once)外部sink系统必须要提供事务
不同sink的一致性保证
Flink CEP
一个或多个由简单事件构成的事件流通过一定的规则匹配,然后输出用户想得到的数据,满足规则的复杂事件。
- 目标:从有序的简单事件流中发现一些高阶特征
- 输入:一个或多个由简单事件构成的事件流
- 处理:识别简单事件之间的内在联系,多个符合一定规则的简单事件构成复杂事件
- 输出:满足规则的复杂事件
CEP用于分析低延迟、频繁产生的不同来源的事件流。CEP可以帮助在复杂的、不相关的事件流中找出有意义的模式和复杂的关系,以接近实时或准实时的获得通知并阻止一些行为。
CEP支持在流上进行模式匹配,根据模式的条件不同,分为连续的条件或不连续的条件;模式的条件允许有时间的限制,当在条件范围内没有达到满足的条件时,会导致模式匹配超时。
功能
- 输入的流数据,尽快产生结果
- 在2个event流上,基于时间进行聚合类的计算
- 提供实时/准实时的警告和通知
- 在多样的数据源中产生关联并分析模式
- 高吞吐、低延迟的处理
Flink SQL
- SQL的几个优点
- 声明式(Declarative)
- 自动调优(Optimized)
- 易于理解(Understandable)
- 稳定(Stable)
- 流与批的统一(Unify)
- Flink SQL的流与批统一总结起来就一句话:One Query,One Result
- 官方文档
Flink SQL核心概念
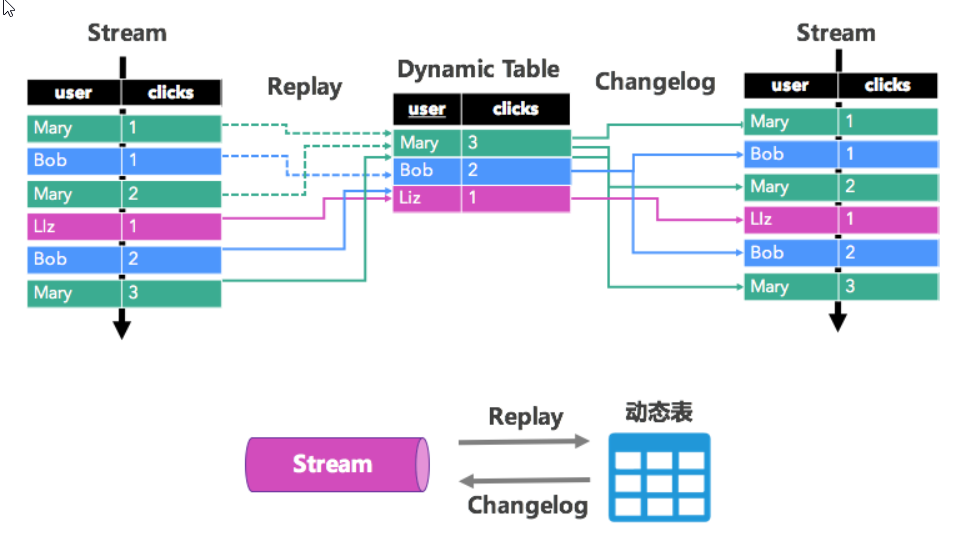
- 动态表&流表二像性
- 传统的SQL是定义在表上的,为了能在流上定义SQL,我们也需要一个表的概念。这里就需要引入一个非常重要的概念:动态表(Dynamic Table)。所谓动态表,就是数据会随着时间变化的表,可以想象成就是数据库中一张被不断更新的表。我们发现流与表有非常紧密的关系,流表可以看作动态表,动态表可以看做流。我们称之为流表二象性。
- 传统的SQL是定义在表上的,为了能在流上定义SQL,我们也需要一个表的概念。这里就需要引入一个非常重要的概念:动态表(Dynamic Table)。所谓动态表,就是数据会随着时间变化的表,可以想象成就是数据库中一张被不断更新的表。我们发现流与表有非常紧密的关系,流表可以看作动态表,动态表可以看做流。我们称之为流表二象性。
- 连续查询
- 动态表是流的另一种表现形式,有了动态表后,我们就可以在流上定义SQL了,流式SQL可以想象成连续查询(Continous Query)。传统的查询是只运行一次的SQL,产生一个结果表就结束了。连续查询会一直运行在那里,当每个数据到来,都会持续增量地更新计算结果,从而产生另一个动态表。而这个结果动态表(也就是流)会作为另一个SQL(连续查询)的输入接着计算,从而串起整个数据流图。
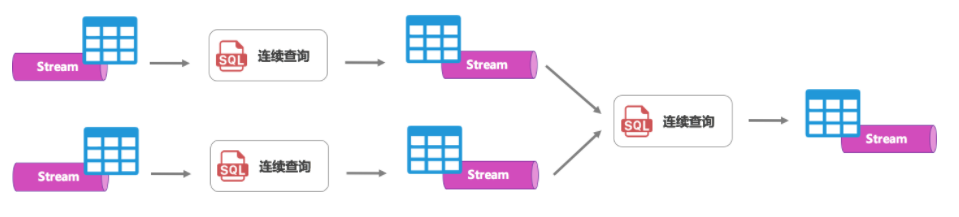
Flink SQL核心功能
- 高级功能
- 双流join
- 双流join功能是将两条流进行关联,用来补齐流上的字段。双流join又分为无限流的双流JOIN和带窗口的双流JOIN
- 维表join
- 维表JOIN功能是流与表的关联,也是用来为数据流补齐字段,只是补齐的维表字段是在外部存储的维表中的。
- TopN
- 全局TopN,分组TopN
- Window
- 支持滚动窗口,滑动窗口,会话窗口,以及传统数据库中的OVER窗口
- 多路输入,多路输出
- MiniBatch 优化
- 对于有状态的算子,每个进入算子的元素都需要对状态做序列化/反序列化的操作,频繁的状态序列化/反序列化操作占了性能开销的大半。MiniBatch的核心思想是,对进入算子的元素进行攒批,一批数据只需要对状态序列化/反序列化一次即可,极大地提升了性能。
- Retraction 撤回机制
- 撤回机制是Flink SQL中一个非常重要地基石,它解决了early-fire导致的结果正确性问题(所有的GroupBy都是early-fire的)。而利用好撤回机制有时候能够很巧妙地帮助业务解决一些特殊需求。
- 双流join
Flink SQL 维表JOIN与异步优化
维表JOIN语法
- 假设我们有一个Orders订单数据流,希望根据产品ID补全流上地产品维度信息,所以需要跟Products维度表进行关联。Orders 和 Products的DDL声明语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29CREATE TABLE Orders (
orderId VARCHAR, -- 订单 id
productId VARCHAR, -- 产品 id
units INT, -- 购买数量
orderTime TIMESTAMP -- 下单时间
) with (
type = 'tt', -- tt 日志流
...
)
CREATE TABLE Products (
productId VARCHAR, -- 产品 id
name VARCHAR, -- 产品名称
unitPrice DOUBLE -- 单价
PERIOD FOR SYSTEM_TIME, -- 这是一张随系统时间而变化的表,用来声明维表
PRIMARY KEY (productId) -- 维表必须声明主键
) with (
type = 'alihbase', -- HBase 数据源
...
)
-- JOIN当前维表
SELECT *
FROM Orders AS o
[LEFT] JOIN Products FOR SYSTEM_TIME AS OF PROCTIME() AS p
ON o.productId = p.productId
-- Flink SQL支持LEFT JOIN和INNER JOIN的维表关联。只是Products维表后面需要跟上FOR SYSTEM_TIME AS OF PROCTIME()的关键字,其含义是每条到达的数据所关联上的是到达时刻的维表快照,也就是说,当数据到达时,我们会根据数据上的Key去查询远程数据库,拿到匹配的结果后关联输出。这里的PROCTIME()即processing time。使用JOIN当前维表功能需要注意的是,如果维表插入了一条数据能匹配上之前左表的数据时,JOIN的结果流,不会发出更新的数据以弥补之前的未匹配。JOIN行为只发生在处理时间(processing time),即使维表中的数据都被删了,之前JOIN流已经发出的关联上的数据也不会被撤回或改变。JOIN当前维表
1
2
3
4SELECT *
FROM Orders AS o
[LEFT] JOIN Products FOR SYSTEM_TIME AS OF PROCTIME() AS p
ON o.productId = p.productId- Flink SQL支持LEFT JOIN和INNER JOIN的维表关联。只是Products维表后面需要跟上FOR SYSTEM_TIME AS OF PROCTIME()的关键字,其含义是每条到达的数据所关联上的是到达时刻的维表快照,也就是说,当数据到达时,我们会根据数据上的Key去查询远程数据库,拿到匹配的结果后关联输出。这里的PROCTIME()即processing time。使用JOIN当前维表功能需要注意的是,如果维表插入了一条数据能匹配上之前左表的数据时,JOIN的结果流,不会发出更新的数据以弥补之前的未匹配。JOIN行为只发生在处理时间(processing time),即使维表中的数据都被删了,之前JOIN流已经发出的关联上的数据也不会被撤回或改变。
JOIN历史维表
1
2
3
4SELECT *
FROM Orders AS o
[LEFT] JOIN Products FOR SYSTEM_TIME AS OF o.orderTime AS p
ON o.productId = p.productId- 有时候想关联上的维度数据,并不是当前时刻的值,而是某个时刻的值。比如,产品的价格一直在发生变化,订单流希望补全的是下单时的价格,而不是当前的价格,那就是JOIN历史维表。语法上只需要将上文的PROCTIME()改成o.orderTime即可。
Flink 在获取维度数据时,会根据左流的时间去查对应时刻的快照数据。因此JOIN历史维表需要外部存储支持多版本存储,如HBase,或者存储的数据中带有多版本信息。
维表优化
- 提高吞吐。维表的IO请求严重阻塞了数据流的计算处理。解决办法:异步IO,原始的维表JOIN是同步访问的方式,来一条数据,去数据库查询一次,等待返回后输出关联结果。可以发现网络等待时间极大地阻碍了吞吐和延迟。为了解决同步访问地问题,异步模式可以并发地处理多个请求和回复,从而连续地请求之间不需要阻塞等待。
- 降低维表数据库读压力。如HBase也只能承受单机每秒20万的读请求。解决办法:进行缓存,LRU和ALL(维表较小,可以将整个维表缓存到本地)
- 通过
cache='LRU'参数可以开启 LRU 缓存优化 - ALL cache 可以通过
cache='ALL'参数开启 - 通过
cacheTTLMs控制缓存的刷新间隔。
Flink sql 支持的语法
insert: INSERT INTO tableReference query query: values | { select | selectWithoutFrom | query UNION [ ALL ] query | query EXCEPT query | query INTERSECT query } [ ORDER BY orderItem [, orderItem ]* ] [ LIMIT { count | ALL } ] [ OFFSET start { ROW | ROWS } ] [ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY] orderItem: expression [ ASC | DESC ] select: SELECT [ ALL | DISTINCT ] { * | projectItem [, projectItem ]* } FROM tableExpression [ WHERE booleanExpression ] [ GROUP BY { groupItem [, groupItem ]* } ] [ HAVING booleanExpression ] [ WINDOW windowName AS windowSpec [, windowName AS windowSpec ]* ] selectWithoutFrom: SELECT [ ALL | DISTINCT ] { * | projectItem [, projectItem ]* } projectItem: expression [ [ AS ] columnAlias ] | tableAlias . * tableExpression: tableReference [, tableReference ]* | tableExpression [ NATURAL ] [ LEFT | RIGHT | FULL ] JOIN tableExpression [ joinCondition ] joinCondition: ON booleanExpression | USING '(' column [, column ]* ')' tableReference: tablePrimary [ [ AS ] alias [ '(' columnAlias [, columnAlias ]* ')' ] ] tablePrimary: [ TABLE ] [ [ catalogName . ] schemaName . ] tableName | LATERAL TABLE '(' functionName '(' expression [, expression ]* ')' ')' | UNNEST '(' expression ')' values: VALUES expression [, expression ]* groupItem: expression | '(' ')' | '(' expression [, expression ]* ')' | CUBE '(' expression [, expression ]* ')' | ROLLUP '(' expression [, expression ]* ')' | GROUPING SETS '(' groupItem [, groupItem ]* ')' windowRef: windowName | windowSpec windowSpec: [ windowName ] '(' [ ORDER BY orderItem [, orderItem ]* ] [ PARTITION BY expression [, expression ]* ] [ RANGE numericOrIntervalExpression {PRECEDING} | ROWS numericExpression {PRECEDING} ] ')'- Hop,滑动窗口,窗口数据有固定大小,有固定的窗口重建频率,窗口数据有叠加1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#### Group Window
* 根据窗口数据划分的不同,目前Flink有如下三种Bounded Window
- Tumble,滚动窗口,窗口数据有固定的大小,窗口数据无叠加
````sqlite
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
/*
[gk] 决定了是否需要按照字段进行聚合;
TUMBLE_START 代表窗口开始时间;
TUMBLE_END 代表窗口结束时间;
timeCol 是流表中表示时间字段;
size 表示窗口的大小,如 秒、分钟、小时、天。
*/
-- 举个例子,假如我们要计算每个人每天的订单量,按照 user 进行聚合分组:
SELECT user,
TUMBLE_START(rowtime, INTERVAL ‘1’ DAY) as wStart,
SUM(amount)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL ‘1’ DAY), user;- Session, 会话窗口,窗口数据没有固定的大小,根据窗口数据活跃程度划分窗口,窗口数据无叠加1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
...
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
/*
[gk] 决定了是否需要按照字段进行聚合;
HOP_START 表示窗口开始时间;
HOP_END 表示窗口结束时间;
timeCol 表示流表中表示时间字段;
slide 表示每次窗口滑动的大小;
size 表示整个窗口的大小,如 秒、分钟、小时、天。
*/
-- 我们要每过一小时计算一次过去 24 小时内每个商品的销量:
SELECT product,
SUM(amount)
FROM Orders
GROUP BY HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '1' DAY), product1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
/*
[gk] 决定了是否需要按照字段进行聚合;
SESSION_START 表示窗口开始时间;
SESSION_END 表示窗口结束时间;
timeCol 表示流表中表示时间字段;
gap 表示窗口数据非活跃周期的时长。
*/
-- 例如,我们需要计算每个用户访问时间 12 小时内的订单量:
SELECT
user,
SESSION_START(rowtime, INTERVAL ‘12’ HOUR) AS sStart,
SESSION_ROWTIME(rowtime, INTERVAL ‘12’ HOUR) AS sEnd,
SUM(amount)
FROM Orders
GROUP BY SESSION(rowtime, INTERVAL ‘12’ HOUR), user
官方文档案例记录
入门
- Flink SQL 使得使用标准 SQL 开发流应用程序变的简单。如果你曾经在工作中使用过兼容 ANSI-SQL 2011 的数据库或类似的 SQL 系统,那么就很容易学习 Flink。
Source表
与所有 SQL 引擎一样,Flink 查询操作是在表上进行。与传统数据库不同,Flink 不在本地管理静态数据;相反,它的查询在外部表上连续运行。
Flink 数据处理流水线开始于 source 表。source 表产生在查询执行期间可以被操作的行;它们是查询时
FROM子句中引用的表。这些表可能是 Kafka 的 topics,数据库,文件系统,或者任何其它 Flink 知道如何消费的系统。Flink 支持不同的连接器和格式相结合以定义表。下面是一个示例,定义一个以 CSV 文件作为存储格式的 source 表,其中
emp_id,name,dept_id作为CREATE表语句中的列。CREATE TABLE employee_information ( emp_id INT, name VARCHAR, dept_id INT ) WITH ( 'connector' = 'filesystem', 'path' = '/path/to/something.csv', 'format' = 'csv' );1
2
3
4
5
6
7
8
9
10
11
12
13
*
##### 连续查询(Transformation)
* 一个[连续查询](https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/dev/table/concepts/dynamic_tables/#continuous-queries)永远不会终止,并会产生一个动态表作为结果。[动态表](https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/dev/table/concepts/dynamic_tables/#continuous-queries)是 Flink 中 Table API 和 SQL 对流数据支持的核心概念。
* ````sqlite
SELECT
dept_id,
COUNT(*) as emp_count
FROM employee_information
GROUP BY dept_id;
Sink表
当运行此查询时,SQL 客户端实时但是以只读方式提供输出。存储结果,作为报表或仪表板的数据来源,需要写到另一个表。这可以使用
INSERT INTO语句来实现。本节中引用的表称为 sink 表。INSERT INTO语句将作为一个独立查询被提交到 Flink 集群中。INSERT INTO department_counts SELECT dept_id, COUNT(*) as emp_count FROM employee_information GROUP BY dept_id;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#### 查询相关内容(DQL)
##### 概览
* `TableEnvironment` 的 `sqlQuery()` 方法可以执行 `SELECT` 和 `VALUES` 语句。 这个方法把 `SELECT` 语句(或 `VALUES` 语句)的结果作为一个 `Table` 返回。 `Table`可以用在[后续 SQL 和 Table API 查询](https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/dev/table/common/#mixing-table-api-and-sql)中,可以[转换为 DataStream](https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/dev/table/common/#integration-with-datastream), 或者 [写入到TableSink](https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/dev/table/common/#emit-a-table)。 SQL 和 Table API 查询可以无缝混合,并进行整体优化并转换为单个程序。
##### Hints
* SQL 提示(SQL Hints)是和 SQL 语句一起使用来改变执行计划的
* 主要作用就是通过一些定制化的hints,优化sql的执行效率
* SQL 提示一般可以用于以下:
- 增强 planner:没有完美的 planner,所以实现 SQL 提示让用户更好地控制执行是非常有意义的;
- 增加元数据(或者统计信息):如"已扫描的表索引"和"一些混洗键(shuffle keys)的倾斜信息"的一些统计数据对于查询来说是动态的,用提示来配置它们会非常方便,因为我们从 planner 获得的计划元数据通常不那么准确;
- 算子(Operator)资源约束:在许多情况下,我们会为执行算子提供默认的资源配置,即最小并行度或托管内存(UDF 资源消耗)或特殊资源需求(GPU 或 SSD 磁盘)等,可以使用 SQL 提示非常灵活地为每个查询(非作业)配置资源。
##### with语句
* sql语句的一个语法糖
````sqlite
WITH orders_with_total AS (
SELECT order_id, price + tax AS total
FROM Orders
)
SELECT order_id, SUM(total)
FROM orders_with_total
GROUP BY order_id;
select where distinct
SELECT order_id, price + tax FROM Orders; SELECT order_id, price FROM (VALUES (1, 2.0), (2, 3.1)) AS t (order_id, price)1
2
3
* ````sqlite
SELECT DISTINCT id FROM Orders对于流式查询, 计算查询结果所需要的状态可能会源源不断地增长,而状态大小又依赖不同行的数量.此时,可以通过配置文件为状态设置合适的存活时间(TTL),以防止过大的状态可能对查询结果的正确性的影响
窗口函数
- Apache Flink 提供了如下
窗口表值函数(table-valued function, 缩写TVF)把表的数据划分到窗口中
滚动窗口(tumble)
TUMBLE函数指定每个元素到一个指定大小的窗口中。滚动窗口的大小固定且不重复。(窗口不断往前滚动)TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])data:拥有时间属性列的表。timecol:列描述符,决定数据的哪个时间属性列应该映射到窗口。size:窗口的大小(时长)。offset:窗口的偏移量 [非必填]。
-- tables must have time attribute, e.g. `bidtime` in this table Flink SQL> desc Bid; +-------------+------------------------+------+-----+--------+---------------------------------+ | name | type | null | key | extras | watermark | +-------------+------------------------+------+-----+--------+---------------------------------+ | bidtime | TIMESTAMP(3) *ROWTIME* | true | | | `bidtime` - INTERVAL '1' SECOND | | price | DECIMAL(10, 2) | true | | | | | item | STRING | true | | | | +-------------+------------------------+------+-----+--------+---------------------------------+ Flink SQL> SELECT * FROM Bid; +------------------+-------+------+ | bidtime | price | item | +------------------+-------+------+ | 2020-04-15 08:05 | 4.00 | C | | 2020-04-15 08:07 | 2.00 | A | | 2020-04-15 08:09 | 5.00 | D | | 2020-04-15 08:11 | 3.00 | B | | 2020-04-15 08:13 | 1.00 | E | | 2020-04-15 08:17 | 6.00 | F | +------------------+-------+------+ Flink SQL> SELECT * FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES)); -- or with the named params -- note: the DATA param must be the first Flink SQL> SELECT * FROM TABLE( TUMBLE( DATA => TABLE Bid, TIMECOL => DESCRIPTOR(bidtime), SIZE => INTERVAL '10' MINUTES)); +------------------+-------+------+------------------+------------------+-------------------------+ | bidtime | price | item | window_start | window_end | window_time | +------------------+-------+------+------------------+------------------+-------------------------+ | 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 | | 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | | 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | | 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 | +------------------+-------+------+------------------+------------------+-------------------------+ -- apply aggregation on the tumbling windowed table Flink SQL> SELECT window_start, window_end, SUM(price) AS total_price FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES)) GROUP BY window_start, window_end; +------------------+------------------+-------------+ | window_start | window_end | total_price | +------------------+------------------+-------------+ | 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 | | 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 | +------------------+------------------+-------------+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
*
###### 滑动窗口 (hop)
* 滑动窗口函数指定元素到一个定长的窗口中。和滚动窗口很像,有窗口大小参数,另外增加了一个窗口滑动步长参数。如果滑动步长小于窗口大小,就能产生数据重叠的效果。在这个例子里,数据可以被分配在多个窗口。(不断的往前滑动相应的步长)
* `HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])`
- `data`:拥有时间属性列的表。
- `timecol`:列描述符,决定数据的哪个时间属性列应该映射到窗口。
- `slide`:窗口的滑动步长。
- `size`:窗口的大小(时长)。
- `offset`:窗口的偏移量 [非必填]。
* ````sqlite
> SELECT * FROM TABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
> SELECT * FROM TABLE(
HOP(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
SLIDE => INTERVAL '5' MINUTES,
SIZE => INTERVAL '10' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:15 | 2020-04-15 08:25 | 2020-04-15 08:24:59.999 |
+------------------+-------+------+------------------+------------------+-------------------------+
-- apply aggregation on the hopping windowed table
> SELECT window_start, window_end, SUM(price) AS total_price
FROM TABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------------+
| window_start | window_end | total_price |
+------------------+------------------+-------------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:05 | 2020-04-15 08:15 | 15.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
| 2020-04-15 08:15 | 2020-04-15 08:25 | 6.00 |
+------------------+------------------+-------------+
累积窗口(cumulate)
- 累积窗口在某些场景中非常有用,比如说提前触发的滚动窗口。例如:每日仪表盘从 00:00 开始每分钟绘制累积 UV,10:00 时 UV 就是从 00:00 到 10:00 的UV 总数。累积窗口可以简单且有效地实现它。
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)data:拥有时间属性列的表。timecol:列描述符,决定数据的哪个时间属性列应该映射到窗口。step:指定连续的累积窗口之间增加的窗口大小。size:指定累积窗口的最大宽度的窗口时间。size必须是step的整数倍。offset:窗口的偏移量 [非必填]。
会话窗口(session)(目前仅支持流模式,v1.20.0)
窗口聚合
会话窗口函数通过会话活动对元素进行分组。与滚动窗口和滑动窗口不同,会话窗口不重叠,也没有固定的开始和结束时间。 一个会话窗口会在一定时间内没有收到元素时关闭,比如超过一定时间不处于活跃状态。 会话窗口需要配置一个固定的会话间隙,以定义不活跃间隙的时长。 当超出不活跃间隙的时候,当前的会话窗口将会关闭,随后的元素将被分配到一个新的会话窗口内。
SESSION(TABLE data [PARTITION BY(keycols, ...)], DESCRIPTOR(timecol), gap)data:拥有时间属性列的表。keycols:列描述符,决定会话窗口应该使用哪些列来分区数据。timecol:列描述符,决定数据的哪个时间属性列应该映射到窗口。gap:两个事件被认为属于同一个会话窗口的最大时间间隔。
/*注意: 会话窗口函数目前不支持批模式。 会话窗口函数目前不支持 性能调优 中的任何优化。 会话窗口 Join 、会话窗口 Top-N 、会话窗口聚合功能目前理论可用,但仍处于实验阶段。遇到问题可以在 JIRA 中报告。 */ -- tables must have time attribute, e.g. `bidtime` in this table Flink SQL> desc Bid; +-------------+------------------------+------+-----+--------+---------------------------------+ | name | type | null | key | extras | watermark | +-------------+------------------------+------+-----+--------+---------------------------------+ | bidtime | TIMESTAMP(3) *ROWTIME* | true | | | `bidtime` - INTERVAL '1' SECOND | | price | DECIMAL(10, 2) | true | | | | | item | STRING | true | | | | +-------------+------------------------+------+-----+--------+---------------------------------+ Flink SQL> SELECT * FROM Bid; +------------------+-------+------+ | bidtime | price | item | +------------------+-------+------+ | 2020-04-15 08:07 | 4.00 | A | | 2020-04-15 08:06 | 2.00 | A | | 2020-04-15 08:09 | 5.00 | B | | 2020-04-15 08:08 | 3.00 | A | | 2020-04-15 08:17 | 1.00 | B | +------------------+-------+------+ -- session window with partition keys > SELECT * FROM TABLE( SESSION(TABLE Bid PARTITION BY item, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES)); -- or with the named params -- note: the DATA param must be the first > SELECT * FROM TABLE( SESSION( DATA => TABLE Bid PARTITION BY item, TIMECOL => DESCRIPTOR(bidtime), GAP => INTERVAL '5' MINUTES); +------------------+-------+------+------------------+------------------+-------------------------+ | bidtime | price | item | window_start | window_end | window_time | +------------------+-------+------+------------------+------------------+-------------------------+ | 2020-04-15 08:07 | 4.00 | A | 2020-04-15 08:06 | 2020-04-15 08:13 | 2020-04-15 08:12:59.999 | | 2020-04-15 08:06 | 2.00 | A | 2020-04-15 08:06 | 2020-04-15 08:13 | 2020-04-15 08:12:59.999 | | 2020-04-15 08:08 | 3.00 | A | 2020-04-15 08:06 | 2020-04-15 08:13 | 2020-04-15 08:12:59.999 | | 2020-04-15 08:09 | 5.00 | B | 2020-04-15 08:09 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 | | 2020-04-15 08:17 | 1.00 | B | 2020-04-15 08:17 | 2020-04-15 08:22 | 2020-04-15 08:21:59.999 | +------------------+-------+------+------------------+------------------+-------------------------+ -- apply aggregation on the session windowed table with partition keys > SELECT window_start, window_end, item, SUM(price) AS total_price FROM TABLE( SESSION(TABLE Bid PARTITION BY item, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES)) GROUP BY item, window_start, window_end; +------------------+------------------+------+-------------+ | window_start | window_end | item | total_price | +------------------+------------------+------+-------------+ | 2020-04-15 08:06 | 2020-04-15 08:13 | A | 9.00 | | 2020-04-15 08:09 | 2020-04-15 08:14 | B | 5.00 | | 2020-04-15 08:17 | 2020-04-15 08:22 | B | 1.00 | +------------------+------------------+------+-------------+ -- session window without partition keys > SELECT * FROM TABLE( SESSION(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES)); -- or with the named params -- note: the DATA param must be the first > SELECT * FROM TABLE( SESSION( DATA => TABLE Bid, TIMECOL => DESCRIPTOR(bidtime), GAP => INTERVAL '5' MINUTES); +------------------+-------+------+------------------+------------------+-------------------------+ | bidtime | price | item | window_start | window_end | window_time | +------------------+-------+------+------------------+------------------+-------------------------+ | 2020-04-15 08:07 | 4.00 | A | 2020-04-15 08:06 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 | | 2020-04-15 08:06 | 2.00 | A | 2020-04-15 08:06 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 | | 2020-04-15 08:08 | 3.00 | A | 2020-04-15 08:06 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 | | 2020-04-15 08:09 | 5.00 | B | 2020-04-15 08:06 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 | | 2020-04-15 08:17 | 1.00 | B | 2020-04-15 08:17 | 2020-04-15 08:22 | 2020-04-15 08:21:59.999 | +------------------+-------+------+------------------+------------------+-------------------------+ -- apply aggregation on the session windowed table without partition keys > SELECT window_start, window_end, SUM(price) AS total_price FROM TABLE( SESSION(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES)) GROUP BY window_start, window_end; +------------------+------------------+-------------+ | window_start | window_end | total_price | +------------------+------------------+-------------+ | 2020-04-15 08:06 | 2020-04-15 08:14 | 14.00 | | 2020-04-15 08:17 | 2020-04-15 08:22 | 1.00 | +------------------+------------------+-------------+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
###### 窗口偏移
* `Offset` 可选参数,可以用来改变窗口的分配。可以是正或者负的区间。默认情况下窗口的偏移是 0。不同的偏移值可以决定记录分配的窗口
##### 窗口聚合
* `GROUPING SETS` 窗口聚合中 `GROUP BY` 子句必须包含 `window_start` 和 `window_end` 列,但 `GROUPING SETS` 子句中不能包含这两个字段。
- 对于rollup和cube的支持也是类似的
* ````sqlite
Flink SQL> SELECT window_start, window_end, supplier_id, SUM(price) AS total_price
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
GROUP BY window_start, window_end, GROUPING SETS ((supplier_id), ());
+------------------+------------------+-------------+-------------+
| window_start | window_end | supplier_id | total_price |
+------------------+------------------+-------------+-------------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | (NULL) | 11.00 |
| 2020-04-15 08:00 | 2020-04-15 08:10 | supplier2 | 5.00 |
| 2020-04-15 08:00 | 2020-04-15 08:10 | supplier1 | 6.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | (NULL) | 10.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | supplier2 | 9.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | supplier1 | 1.00 |
+------------------+------------------+-------------+-------------+多级窗口聚合
window_start和window_end列是普通的时间戳字段,并不是时间属性。因此它们不能在后续的操作中当做时间属性进行基于时间的操作。 为了传递时间属性,需要在GROUP BY子句中添加window_time列。window_time是 Windowing TVFs 产生的三列之一,它是窗口的时间属性。window_time添加到GROUP BY子句后就能被选定了。-- tumbling 5 minutes for each supplier_id CREATE VIEW window1 AS -- Note: The window start and window end fields of inner Window TVF are optional in the select clause. However, if they appear in the clause, they need to be aliased to prevent name conflicting with the window start and window end of the outer Window TVF. SELECT window_start AS window_5mintumble_start, window_end AS window_5mintumble_end, window_time AS rowtime, SUM(price) AS partial_price FROM TABLE( TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES)) GROUP BY supplier_id, window_start, window_end, window_time; -- tumbling 10 minutes on the first window SELECT window_start, window_end, SUM(partial_price) AS total_price FROM TABLE( TUMBLE(TABLE window1, DESCRIPTOR(rowtime), INTERVAL '10' MINUTES)) GROUP BY window_start, window_end;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
-
##### 分组聚合
* sql常用的分组聚合操作都是支持的、group by,count(distinct ),grouping sets维度组合聚合,having过滤等
* ````sqlite
SELECT COUNT(*)
FROM Orders
GROUP BY order_id
SELECT COUNT(DISTINCT order_id) FROM Orders
SELECT supplier_id, rating, COUNT(*) AS total
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS ((supplier_id, rating), (supplier_id), ())
SELECT SUM(amount)
FROM Orders
GROUP BY users
HAVING SUM(amount) > 50
over聚合
OVER聚合通过排序后的范围数据为每行输入计算出聚合值。和GROUP BY聚合不同,OVER聚合不会把结果通过分组减少到一行,它会为每行输入增加一个聚合值。-- 下面这个查询为每个订单计算前一个小时之内接收到的同一产品所有订单的总金额。 SELECT order_id, order_time, amount, SUM(amount) OVER ( PARTITION BY product ORDER BY order_time RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW ) AS one_hour_prod_amount_sum FROM Orders1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
* 特殊点:
- 你可以在一个 `SELECT` 子句中定义多个 `OVER` 窗口聚合。然而,对于流式查询,由于目前的限制,所有聚合的 `OVER` 窗口必须是相同的。
- Flink 目前只支持 `OVER` 窗口定义在升序(asc)的 [时间属性](https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/dev/table/concepts/time_attributes/) 上。其他的排序不支持。
- 范围(RANGE)定义指定了聚合中包含了多少行数据。范围通过 `BETWEEN` 子句定义上下边界,其内的所有行都会聚合。Flink 只支持 `CURRENT ROW` 作为上边界。
- RANGE间隔
- `RANGE` 间隔是定义在排序列值上的,在 Flink 里,排序列总是一个时间属性。下面的 `RANG` 间隔定义了聚合会在比当前行的时间属性小 30 分钟的所有行上进行。
- ```sql
RANGE BETWEEN INTERVAL '30' MINUTE PRECEDING AND CURRENT ROW
```
- ROW间隔
- `ROWS` 间隔基于计数。它定义了聚合操作包含的精确行数。下面的 `ROWS` 间隔定义了当前行 + 之前的 10 行(也就是11行)都会被聚合。
- ```sqlite
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
WINDOW
```
- WINDOW子句的使用
- ```sqlite
SELECT order_id, order_time, amount,
SUM(amount) OVER w AS sum_amount,
AVG(amount) OVER w AS avg_amount
FROM Orders
WINDOW w AS (
PARTITION BY product
ORDER BY order_time
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW)
```
##### join
* Flink SQL支持对动态表进行复杂而灵活的连接操作。 为了处理不同的场景,需要多种查询语义,因此有几种不同类型的 Join。
* 默认情况下,joins 的顺序是没有优化的。表的 join 顺序是在 `FROM` 从句指定的。可以通过把更新频率最低的表放在第一个、频率最高的放在最后这种方式来微调 join 查询的性能。需要确保表的顺序不会产生笛卡尔积,因为不支持这样的操作并且会导致查询失败。
###### Regular Joins
###### Interval Joins
###### Temporal Joins
###### Lookup Join
###### 数组展开
###### Table Function
##### 窗口关联
* 窗口关联就是增加时间维度到关联条件中。在此过程中,窗口关联将两个流中在同一窗口且符合 join 条件的元素 join 起来。窗口关联的语义和 [DataStream window join](https://nightlies.apache.org/flink/flink-docs-release-1.20/zh/docs/dev/datastream/operators/joining/#window-join) 相同。
##### 集合操作
* UNION,INTERSECT,EXCEPT,IN,EXISTS
* ````sqlite
Flink SQL> create view t1(s) as values ('c'), ('a'), ('b'), ('b'), ('c');
Flink SQL> create view t2(s) as values ('d'), ('e'), ('a'), ('b'), ('b');
-- INTERSECT 和 INTERSECT ALL 返回两个表中共有的数据。 INTERSECT 会去重,INTERSECT ALL 不会去重。
(SELECT s FROM t1) INTERSECT (SELECT s FROM t2);
-- EXCEPT 和 EXCEPT ALL 返回在一个表中存在,但在另一个表中不存在数据。 EXCEPT 会去重,EXCEPT ALL不会去重。
(SELECT s FROM t1) EXCEPT (SELECT s FROM t2);
SELECT user, amount
FROM Orders
WHERE product IN (
SELECT product FROM NewProducts
)
SELECT user, amount
FROM Orders
WHERE product EXISTS (
SELECT product FROM NewProducts
)
order by语句
limit语句
Top-N
窗口Top-N
窗口去重
去重
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!