StarRocks
本文最后更新于:2024年8月19日 晚上
StarRocks
基础介绍
- 社区还是很活跃的,贴一下官方文档:StarRocks官方文档
- 官方描述:StarRocks 是一款高性能分析型数据库,使用向量化、MPP 架构、CBO、智能物化视图、可实时更新的列式存储引擎等技术实现多维、实时、高并发的数据分析。StarRocks 既支持从各类实时和离线的数据源高效导入数据,也支持直接分析数据湖上各种格式的数据。StarRocks 兼容 MySQL 协议,可使用 MySQL 客户端和常用 BI 工具对接。同时 StarRocks 具备水平扩展,高可用、高可靠、易运维等特性。广泛应用于实时数仓、OLAP 报表、数据湖分析等场景。
- StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库。StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。
- StarRocks 架构简洁,采用了全面向量化引擎,并配备全新设计的 CBO (Cost Based Optimizer) 优化器,查询速度(尤其是多表关联查询)远超同类产品。
适用场景
- StarRocks 可以满足企业级用户的多种分析需求,包括 OLAP (Online Analytical Processing) 多维分析、定制报表、实时数据分析和 Ad-hoc 数据分析等。
- OLAP多维分析:利用 StarRocks 的 MPP 框架和向量化执行引擎,用户可以灵活的选择雪花模型,星型模型,宽表模型或者预聚合模型。适用于灵活配置的多维分析报表,业务场景包括:
- 用户行为分析
- 用户画像、标签分析、圈人
- 自助式报表平台
- 系统监控分析
- 实时数据仓库:StarRocks 设计和实现了 Primary-Key 模型,能够实时更新数据并极速查询,可以秒级同步 TP (Transaction Processing) 数据库的变化,构建实时数仓,业务场景包括:
- 电商大促数据分析
- 物流行业的运单分析
- 金融行业绩效分析、指标计算
- 高并发查询:StarRocks 通过良好的数据分布特性,灵活的索引以及物化视图等特性,可以解决面向用户侧的分析场景,业务场景包括
- 广告主报表分析
- SaaS 行业面向用户分析报表
- 统一分析:
- 通过使用一套系统解决多维分析、高并发查询、预计算、实时分析查询等场景,降低系统复杂度和多技术栈开发与维护成本。
- 使用 StarRocks 统一管理数据湖和数据仓库,将高并发和实时性要求很高的业务放在 StarRocks 中分析,也可以使用 External Catalog 和外部表进行数据湖上的分析。
系统架构
- 架构简洁,核心只有FE(Frontend),BE(Backend)或CN(Compute Node)两类进程,方便部署维护,可水平扩展,有副本机制,确保系统无单点。SR支持Mysql协议接口,支持SQL标准语法。
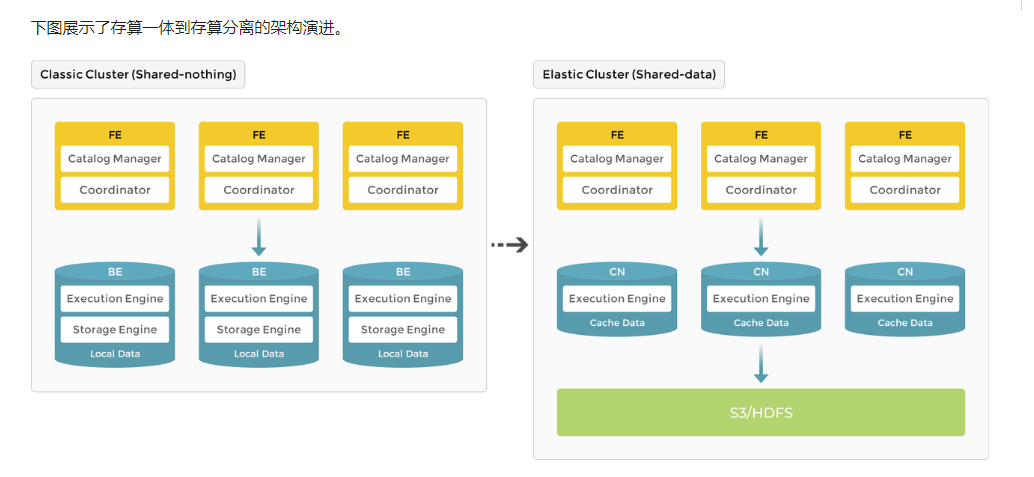
- FE 节点负责元数据管理、客户端连接管理、查询计划和查询调度。每个 FE 在其内存中存储和维护完整的元数据副本,确保每个 FE 都能提供无差别的服务。
- CN 节点在存算分离或存算一体集群中负责执行查询。
- BE 节点在存算一体集群中负责数据存储和执行查询。
- 执行sql时,一条sql 语句首先会按照语义规划成逻辑单元,然后再按照数据的分布情况拆分成具体的物理执行单元。物理执行单元会在对应的BE节点上执行,实现本地计算,避免数据的传输与拷贝,加速查询
- 从存算一体(shared-nothing)进化到存算分离(shared-data)
- 3.0 版本之前使用存算一体架构,BE 同时负责数据存储和计算,数据访问和分析都在本地进行,提供极速的查询分析体验。
- 3.0 版本开始引入存算分离架构,数据存储功能从原来的 BE 中抽离,BE 节点升级为无状态的 CN 节点。数据可持久存储在远端对象存储或 HDFS 上,CN 本地磁盘只用于缓存热数据来加速查询。存算分离架构下支持动态增删计算节点,实现秒级的扩缩容能力。
- 存算分离支持的存储系统:兼容 AWS S3 协议的对象存储系统;Azure Blob Storage;传统数据中心部署的 HDFS
数据管理
SR采用列式存储,采用分区分桶机制进行数据管理。一张表可以被划分成多个分区,一个分区内的数据可以根据一列或者多列进行分桶,将数据切分成多个Tablet。tablet是SR中最小的数据管理单元,每个tablet都会以多副本的形式存储在不同的BE节点中。用户可以指定Tablet 的个数和大小,SR会管理好每个Tablet 副本的分布信息。(Tablet实际就是数据分桶)
下面是StarRocks 的数据划分以及 Tablet 多副本机制。表按照日期划分为 4 个分区,第一个分区进一步切分成 4 个 Tablet。每个 Tablet 使用 3 副本进行备份,分布在 3 个不同的 BE 节点上。
解释一下catlog的作用,以Flink Catalog为例:
Catalog 提供了一个统一的 API 来管理元数据,并使其可以从表 API 和 SQL 查询语句中来访问。
Catalog 使用户能够引用他们数据系统中的现有元数据,并自动将它们映射到 Flink 的相应元数据。
例如,Flink 可以将 JDBC 表自动映射到 Flink 表,用户不必在 Flink 中手动重写 DDL。Catalog 大大简化了用户现有系统开始使用 Flink 所需的步骤,并增强了用户体验。
schema的作用:schema是对一个数据库的结构描述。在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。
缓存:为了提升存算分离架构的查询性能,SR构建了分级的数据缓存体系,将最热的数据缓存在内存中,距离计算最近;次热数据则缓存在本地磁盘,冷数据位于对象存储,数据根据访问频率在三级存储中自由流动。
具体细节:
StarRocks 存算分离的统一缓存允许用户在建表时决定是否开启缓存。如果开启,数据写入时会同步写入本地磁盘以及后端对象存储,查询时,CN 节点会优先从本地磁盘读取数据,如果未命中,再从后端对象存储读取原始数据并同时缓存在本地磁盘。
同时,针对未被缓存的冷数据,StarRocks 也进行了针对性优化,可根据应用访问模式,利用数据预读技术、并行扫描技术等手段,减少对于后端对象存储的访问频次,提升查询性能。

产品特性
- MPP分布式执行框架
- StarRocks 采用 MPP (Massively Parallel Processing) 分布式执行框架。在MPP执行框架中,一条查询请求会被拆分成多个物理计算单元,在多机并行执行。每个执行节点拥有独享的资源(CPU、内存)。
- 不同逻辑执行单元可以由不同数目的物理执行单元来具体执行,以提高资源使用率,提升查询速度。
- 在 MPP 框架中,数据会被 Shuffle 到多个节点,并且由多个节点来完成最后的汇总计算。
- 全面向量化执行引擎
- StarRocks 通过实现全面向量化引擎,充分发挥了 CPU 的处理能力。全面向量化引擎按照列式的方式组织和处理数据。StarRocks 的数据存储、内存中数据的组织方式,以及 SQL 算子的计算方式,都是列式实现的。按列的数据组织也会更加充分的利用 CPU 的 Cache,按列计算会有更少的虚函数调用以及更少的分支判断从而获得更加充分的 CPU 指令流水。
- 存储计算分离
- 存算分离,存储与计算解耦,独立扩缩容
- CBO优化器
- 厉害的查询优化器,选择出相对最优的查询计划
- 可实时更新的列式存储引擎
- 实现列式存储,数据以列的方式存储,相同类型的数据连续存放
- 提高压缩比,降低I/O式的总量,提升查询性能
- StarRocks 能够支持秒级的导入延迟,提供准实时的服务能力。StarRocks 的存储引擎在数据导入时能够保证每一次操作的 ACID。一个批次的导入数据生效是原子性的,要么全部导入成功,要么全部失败
- 智能物化视图
- SR物化视图可以根据原始表更新数据,只要原始表发生变化,物化视图会同步更新,不需要额外的维护操作就可以保证物化视图能够维持与原表一致
- 物化视图的选择也是自动进行的。StarRocks 在进行查询规划时,如果有合适的物化视图能够加速查询,StarRocks 自动进行查询改写(query rewrite),将查询自动定位到最适合的物化视图上进行查询加速。
- 数据湖分析
- StarRocks 不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据。
- 利用SR的提供的 External Catalog,轻松查询存储在Apache Hive、Apache Iceberg、Apache Hudi、Delta Lake 等数据湖上的数据
- 在数据湖分析场景中,StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护。使用数据湖的优势在于可以使用开放的存储格式和灵活多变的 schema 定义方式,可以让 BI/AI/Adhoc/报表等业务有统一的 single source of truth。
表设计
SR使用Internal Catlog来管理内部数据,使用 External Catalog 来连接数据湖中的数据。存储在SR中的数据都包含在Internal Catlog下,Internal Catalog 可以包含一个或多个数据库。数据库用于存储、管理和操作 StarRocks 中的数据,可用于管理多种对象,包括表、物化视图、视图等。StarRocks 采用权限系统来管理数据访问权限,定义了用户对哪些对象可以执行哪些操作,提高数据安全性。
Catalog 分为 Internal catalog 和 External catalog。Internal catalog 是内部数据目录,用于管理导入至 StarRocks 中的数据以及内部的物化视图等。每个集群都有且只有一个名为 default_catalog 的 Internal catalog,包含一个或多个数据库。StarRocks 作为数据仓库存储数据,能够显著提高查询性能,尤其应对大规模数据的复杂查询分析。
External catalog 是外部数据目录,用于连接数据湖中的数据。您可以将 StarRocks 作为查询引擎,直接查询湖上数据,无需导入数据至 StarRocks。
StarRocks 中的表分为两类:内部表和外部表。
内部表归属于 Internal catalog 的数据库,数据保存在 StarRocks 中。内部表由行和列构成,每一行数据是一条记录。
- 在 StarRocks 中,根据约束的类型将内部表分四种,分别是主键表、明细表、聚合表和更新表,适用于存储和查询多种业务场景中的数据,比如原始日志、实时数据、以及汇总数据。
- 内部表采用分区+分桶的两级数据分布策略,实现数据均匀分布。并且分桶以多副本形式均匀分布至 BE 节点,保证数据高可用。
外部表是 External catalog 中的表,实际数据存在外部数据源中,StarRocks 只保存表对应的元数据,您可以通过外部表查询外部数据。
物化视图
- 物化视图是特殊的物理表,能够存储基于基表的预计算结果。当您对基表执行复杂查询时,StarRocks可以自动复用物化视图中的预计算结果,实现查询透明加速,湖仓加速和数据建模等业务需求。
- 视图(也叫逻辑视图)是虚拟表,不存储数据,其中所展示的数据来自于基表生成的查询结果。每次在查询中引用某个视图时,都会运行定义该视图的查询。
- SR有权限系统,权限决定了哪些用户可以对哪些特定对象执行哪些特定的操作。SR采用两种权限模型:基于用户标识的访问控制和基于角色的访问控制。您可以将权限赋予给角色然后通过角色传递权限给用户,或直接赋予权限给用户标识。
- 存算分离架构,数据存储功能从原来的BE中抽离,数据可持久存储在更为可靠廉价的远端对象存储(如S3(AWS S3 全名是 Simple Storage Service,简便的存储服务。亚马逊的云存储业务))或HDFS上,本地磁盘只用于缓存热数据来加速查询
表概览
- 表是数据存储单元。理解 StarRocks 中的表结构,以及如何设计合理的表结构,有利于优化数据组织,提高查询效率。相比于传统的数据库,StarRocks 会以列的方式存储 JSON、ARRAY 等复杂的半结构化数据,保证高效查询。
表类型
- SR提供四种类型的表,包括明细表,主键表,聚合表和更新表,使用于存储多种业务数据。
- 明细表简单易用,表中数据不具有任何约束,相同的数据行可以重复存在。适用于存储不需要约束和预聚合的原始数据。
- 主键表能力强大,具有唯一性非空约束。该表能够支撑实时更新,部分列更新等场景的同时,保证查询性能,使用于实时查询。
- 聚合表适用于存储预聚合后的数据,可以降低聚合查询时所需扫描和计算的数据量,极大的提高聚合查询的效率。
- 更新表适用于实时更新的业务场景,目前已逐渐被主键表取代。
数据分布
- SR采用分区+分桶的两级数据分布策略,将数据均匀分布各个BE节点。查询时能够有效裁剪数据扫描量,最大限度的利用集群的并发性能。
分区
- 第一层级为分区,表中数据可以根据分区列(通常是时间和日期)分成一个个更小的数据管理单元。查询时,通过分区裁剪,可以减少扫描的数据量,显著优化查询性能。
- SR提供简单易用的表达式分区。还提供更加灵活的分区方式,Range分区和List分区。
分桶
- 第二层级为分桶,同一个分区中的数据通过分桶,划分成更小的数据管理单元。并且分桶以多副本的形式均匀分布在BE节点上,保证数据的高可用。
- SR有两种分桶方式:
- 哈希分桶:根据数据的分桶键值,将数据划分至分桶。选择查询时经常使用的条件组成分桶键,能够有效的提高查询效率。
- 随机分桶:随机划分数据至分桶,这种方式更加简单易用。
数据类型
- 支持多种数据类型,和hive差不多
索引
- 索引是一种特殊的数据结构,相当于数据的目录。
- SR提供内置索引,包括前缀索引,Ordinal索引和ZoneMap索引。也支持手动创建索引,提高查询效率,包括Bitmap和Bloom Filter索引。
约束
- 约束用于确保数据的完整性、一致性和准确性。主键表的 Primary Key 列具有唯一非空约束,聚合表的 Aggregate Key 列和更新表的 Unique Key 列具有唯一约束。
表类型
基础信息
- 四种表类型:分别是明细表 (Duplicate key table)、聚合表 (Aggregate table)、更新表 (Unique Key table) 和主键表 ( Primary Key table)。
排序键
- 数据导入至使用某个类型的表,会按照建表时指定的一列或多列排序后存储,这部分用于排序的列就称为排序键。排序键通常为查询时过滤条件频繁使用的一个或者多个列,用以加速查询。 明细表中,数据按照排序键
DUPLICATE KEY排序,并且排序键不需要满足唯一性约束。 聚合表中,数据按照排序键AGGREGATE KEY聚合后排序,并且排序键需要满足唯一性约束。 更新表中,数据按照排序键UNIQUE KEYREPLACE 后排序,并且排序键需要满足唯一性约束。 主键表支持分别定义主键和排序键,主键PRIMARY KEY需要满足唯一性和非空约束,主键相同的数据进行 REPLACE。排序键是用于排序,由ORDER BY指定 。 - 在建表语句中,排序键必须定义在其他列之前。
- 在创建表时,您可以将一个或多个列定义为排序键。排序键在建表语句中的出现次序,为数据存储时多重排序的次序。
- 不支持排序键的数据类型为 BITMAP、HLL。
- 前缀索引的长度限制为 36 字节。如果排序键中全部列的值的长度加起来超过 36 字节,则前缀索引仅会保存限制范围内排序键的若干前缀列。
- 如果导入的数据存在重复的主键,则数据导入至不同类型的表时,存储在 StarRocks 时,则会按照如下方式进行处理:
- 明细表:表中会存在主键重复的数据行,并且与导入的数据是完全对应的。您可以召回所导入的全部历史数据。
- 聚合表:表中不存在主键重复的数据行,主键满足唯一性约束。导入的数据中主键重复的数据行聚合为一行,即具有相同主键的指标列,会通过聚合函数进行聚合。您只能召回导入的全部历史数据的聚合结果,但是无法召回历史明细数据。
- 主键表和更新表:表中不存在主键重复的数据行,主键满足唯一性约束。最新导入的数据行,替换掉其他主键重复的数据行。这两种类型的表可以视为聚合表的特殊情况,相当于在聚合表中,为表的指标列指定聚合函数为 REPLACE,REPLACE 函数返回主键相同的一组数据中的最新数据。
明细表
明细表是默认创建的表类型。如果在建表时未指定任何key,默认创建的是明细表
创建表时,支持定义排序键。如果查询的过滤条件包含排序键,则 StarRocks 能够快速地过滤数据,提高查询效率。明细表适用于日志数据分析等场景,支持追加新数据,不支持修改历史数据。
建表语句
1
2
3
4
5
6
7
8
9
10
11
12CREATE TABLE IF NOT EXISTS detail (
event_time DATETIME NOT NULL COMMENT "datetime of event",
event_type INT NOT NULL COMMENT "type of event",
user_id INT COMMENT "id of user",
device_code INT COMMENT "device code",
channel INT COMMENT ""
)
DUPLICATE KEY(event_time, event_type)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
"replication_num" = "3"
);排序键的相关说明:
在建表语句中,排序键必须定义在其他列之前。
排序键可以通过
DUPLICATE KEY显式定义。本示例中排序键为event_time和event_type。如果未指定,则默认选择表的前三列作为排序键。
明细表中的排序键可以为部分或全部维度列。
建表时,支持为指标列创建 BITMAP、Bloom Filter 等索引。
聚合表
建表时,支持定义排序键和指标列,并为指标列指定聚合函数。当多条数据具有相同的排序键时,指标列会进行聚合。在分析统计和汇总数据时,聚合表能够减少查询时所需要处理的数据,提升查询效率。
适用于分析统计和汇总数据
原理:从数据导入至数据查询阶段,聚合表内部同一排序键的数据会多次聚合,步骤:
- 数据导入阶段:数据按批次导入至聚合表时,每一个批次的数据形成一个版本。在一个版本中,同一排序键的数据会进行一次聚合
- 后台文件合并阶段(Compaction):数据分批次多次导入至聚合表中,会生成多个版本的文件,多个版本的文件定期合并成一个大版本文件时,同一排序键的数据会进行一次聚合。
- 查询阶段:所有版本中同一排序键的数据进行聚合,然后返回查询结果
聚合表中数据进行多次聚合,能够减少查询时所需要处理的数据量,进而提升查询的效率
创建表
1
2
3
4
5
6
7
8
9
10
11
12
13
14/*
例如需要分析某一段时间内,来自不同城市的用户,访问不同网页的总次数。则可以将网页地址 site_id、日期 date 和城市代码 city_code 作为排序键,将访问次数 pv 作为指标列,并为指标列 pv 指定聚合函数为 SUM。
*/
CREATE TABLE IF NOT EXISTS example_db.aggregate_tbl (
site_id LARGEINT NOT NULL COMMENT "id of site",
date DATE NOT NULL COMMENT "time of event",
city_code VARCHAR(20) COMMENT "city_code of user",
pv BIGINT SUM DEFAULT "0" COMMENT "total page views"
)
AGGREGATE KEY(site_id, date, city_code)
DISTRIBUTED BY HASH(site_id)
PROPERTIES (
"replication_num" = "3"
);建表时必须使用
DISTRIBUTED BY HASH子句指定分桶键。分桶键的更多说明,请参见分桶。自 2.5.7 版本起,StarRocks 支持在建表和新增分区时自动设置分桶数量 (BUCKETS),您无需手动设置分桶数量。更多信息,请参见 设置分桶数量。
排序键的相关说明:
在建表语句中,排序键必须定义在其他列之前。
排序键可以通过
AGGREGATE KEY显式定义。- 如果
AGGREGATE KEY未包含全部维度列(除指标列之外的列),则建表会失败。 - 如果不通过
AGGREGATE KEY显示定义排序键,则默认除指标列之外的列均为排序键。
- 如果
排序键必须满足唯一性约束,必须包含全部维度列,并且列的值不会更新。
指标列:通过在列名后指定聚合函数,定义该列为指标列。一般为需要汇总统计的数据。
聚合函数:指标列使用的聚合函数。聚合表支持的聚合函数,请参见 CREATE TABLE。
查询时,排序键在多版聚合之前就能进行过滤,而指标列的过滤在多版本聚合之后。因此建议将频繁使用的过滤字段作为排序键,在聚合前就能过滤数据,从而提升查询性能。
建表时,不支持为指标列创建 BITMAP、Bloom Filter 等索引。
更新表
建表时,支持定义主键和指标列,查询时返回主键相同的一组数据中的最新数据。相对于明细表,更新表简化了数据导入流程,能够更好地支撑实时和频繁更新的场景。
建表
1
2
3
4
5
6
7
8
9
10
11CREATE TABLE IF NOT EXISTS orders (
create_time DATE NOT NULL COMMENT "create time of an order",
order_id BIGINT NOT NULL COMMENT "id of an order",
order_state INT COMMENT "state of an order",
total_price BIGINT COMMENT "price of an order"
)
UNIQUE KEY(create_time, order_id)
DISTRIBUTED BY HASH(order_id)
PROPERTIES (
"replication_num" = "3"
);
主键表
主键表支持分别定义主键和排序键。数据导入至主键表时先按照排序键排序后存储。查询时返回主键相同的一组数据中的最新数据。相对于更新表,主键表在查询时不需要执行聚合操作,并且支持谓词和索引下推,能够在支持实时和频繁更新等场景的同时,提供高效查询。
适用场景:
- 实时对接事务型数据至StarRocks。通过 Flink-CDC 等工具直接对接 TP 的 Binlog,实时同步增删改的数据至主键表,可以简化数据同步流程,并且相对于 Merge-On-Read 策略的更新表,查询性能能够提升 3~10 倍。
- 利用部分列更新轻松实现多流JOIN。在用户画像等分析场景中,一般会采用大宽表方式来提升多维分析的性能,同时简化数据分析师的使用模型。而这种场景中的上游数据,往往可能来自于多个不同业务(比如来自购物消费业务、快递业务、银行业务等)或系统(比如计算用户不同标签属性的机器学习系统),主键表的部分列更新功能就很好地满足这种需求,不同业务直接各自按需更新与业务相关的列即可,并且继续享受主键表的实时同步增删改数据及高效的查询性能。
注意事项:
单条主键编码后的最大长度为128字节,开启持久化索引,可以大大降低主键对内存的占用。因为少部分主键索引存在内存中,大部分主键索引存在磁盘中。
应用场景:
数据有冷热特征,即最近几天的热数据才经常被修改,老的冷数据很少被修改。
大宽表(数百到数千列)。主键只占整个数据的很小一部分,其内存开销比较低。比如用户状态和画像表,虽然列非常多,但总的用户数不大(千万至亿级别),主键索引内存占用相对可控。
案例
create table users ( user_id bigint NOT NULL, name string NOT NULL, email string NULL, address string NULL, age tinyint NULL, sex tinyint NULL, last_active datetime, property0 tinyint NOT NULL, property1 tinyint NOT NULL, property2 tinyint NOT NULL, property3 tinyint NOT NULL ) PRIMARY KEY (user_id) DISTRIBUTED BY HASH(user_id) ORDER BY(`address`,`last_active`) PROPERTIES ( "replication_num" = "3", "enable_persistent_index" = "true" ); -- 建表时必须使用ISTRIBUTED BY HASH 子句指定分桶键,否则建表失败 -- 自 2.5.7 版本起,StarRocks 支持在建表和新增分区时自动设置分桶数量 (BUCKETS),您无需手动设置分桶数量1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
- 主键表相关说明
- 在建表语句中,主键必须定义在其他列之前。
- 主键通过 `PRIMARY KEY` 定义。
- 主键必须满足唯一性约束,且列的值不会修改。本示例中主键为 `dt`、`order_id`。
- 主键支持以下数据类型:BOOLEAN、TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DATE、DATETIME、VARCHAR/STRING。并且不允许为 NULL。
- 分区列和分桶列必须在主键中。
- `enable_persistent_index`:是否持久化主键索引,同时使用磁盘和内存存储主键索引,避免主键索引占用过大内存空间。
- 可以在建表时,在`PROPERTIES`中配置该参数,取值范围为 `true` 或者 `false`(默认值)。
- 如果磁盘为固态硬盘 SSD,则建议设置为 `true`。如果磁盘为机械硬盘 HDD,并且导入频率不高,则也可以设置为 `true`。
- 如果不开启持久化,可能会导致占用内存较多,建议合理设置主键,防治内存溢出,建议先进行内存占用的计算:(12 + 9(每行固定开销) ) * 1000W * 3 * 1.5(哈希表平均额外开销) = 945 M
### 数据分布
* 合理设置分区和分桶,实现数据均匀分布和查询性能提升。
#### 常见的数据分布方式
* 现代分布式数据库中,常见的数据分布方式有:Round-Robin,Range,LIst和Hash
- [](https://imgse.com/i/pFR8OhR)
- Round-Robin:以轮询的方式把数据逐个放置在相邻节点上
- Range:按区间进行数据分布,如图所示,区间[1-3],[4-6]分别对应不同的范围(Range)
- List:直接基于离散的各个取值做数据分布。比如性别,省份等数据就满足这种离散的特性
- Hash:通过哈希函数把数据映射到不同节点上
* 还可以根据业务场景需求组合使用这些数据分方式。常见的组合方式有 Hash+Hash、Range+Hash、Hash+List。
#### SR的数据分布方式
* SR支持单独和组合使用数据分布方式
* SR通过分区+分桶的方式来实现数据分布
- 第一层为分区:在一张表中,可以进行分区,支持的分区方式有表达式分区,Range分区和List分区,或者不分区
- 第二层为分桶:在一个分区中,必须进行分桶,支持的分桶方式有哈希分桶和随机分桶
#### 创建分区
* 表达式分区
- 您仅需要在建表时使用分区表达式(时间函数表达式或列表达式),即可实现导入数据时自动创建分区,不需要预先创建出分区或者配置动态分区属性。
* Range分区
- Range 分区适用于简单且具有连续性的数据
* 动态分区
- 区别于表达式分区中自动创建分区功能,动态创建分区只是根据您配置的动态分区属性,定期提前创建一些分区。
##### 批量创建分区
* 建表时和建表后,支持批量创建分区,通过 START、END 指定批量分区的开始和结束,EVERY 子句指定分区增量值。其中,批量分区包含 START 的值,但是不包含 END 的值。分区的命名规则同动态分区一样。
#### 管理分区
* 增加分区
- 对于 Range 分区和 List 分区,您可以手动增加新的分区,用于存储新的数据,而表达式分区可以实现导入新数据时自动创建分区,您无需手动新增分区。 新增分区的默认分桶数量和原分区相同。您也可以根据新分区的数据规模调整分桶数量。
- ````sql
ALTER TABLE site_access
ADD PARTITION p4 VALUES LESS THAN ("2020-04-30")
DISTRIBUTED BY HASH(site_id);
删除分区
- 分区中的数据不会立即删除,会在Trash中保留一段时间(默认为一天)
1
2ALTER TABLE site_access
DROP PARTITION p1;恢复分区
1
RECOVER PARTITION p1 FROM site_access;查看分区
1
SHOW PARTITIONS FROM site_access;
设置分桶
随机分桶
- 对每个分区的数据,StarRocks 将数据随机地分布在所有分桶中,适用于数据量不大,对查询性能要求不高的场景。如果您不设置分桶方式,则默认由 StarRocks 使用随机分桶,并且自动设置分桶数量。
哈希分桶
- 对每个分区的数据,StarRocks 会根据分桶键和分桶数量进行哈希分桶。在哈希分桶中,使用特定的列值作为输入,通过哈希函数计算出一个哈希值,然后将数据根据该哈希值分配到相应的桶中。
- 优点
- 提高查询性能。相同分桶键值的行会被分配到一个分桶中,在查询时能减少扫描数据量。
- 均匀分布数据。通过选取较高基数(唯一值的数量较多)的列作为分桶键,能更均匀的分布数据到每一个分桶中。
- 选择分桶键
- 假设存在列同时满足高基数和经常作为查询条件,则建议您选择其为分桶键,进行哈希分桶。若不存在这样的列,根据查询进行判断
- 如果查询复杂,建议选择高基数的列为分桶键,保证数据在各个分桶中尽量均衡,提高资源利用率。
- 如果查询比较简单,则建议选择经常作为查询条件的列为分桶键,提高查询效率
- 如果数据倾斜很严重,可以选择多个列作为数据的分桶键,建议不超过三个列
- 假设存在列同时满足高基数和经常作为查询条件,则建议您选择其为分桶键,进行哈希分桶。若不存在这样的列,根据查询进行判断
- 设置分桶数
- 自 2.5.7 版本起,StarRocks 支持根据机器资源和数据量自动设置分区中分桶数量。
- 如果表单个分区原始数据规模预计超过 100 GB,建议您手动设置分区中分桶数量。如果需要开启并行扫描 Tablet,则您需要确保系统变量
enable_tablet_internal_parallel全局生效SET GLOBAL enable_tablet_internal_parallel = true;。首先预估每个分区的数据量,然后按照每10GB原始数据一个Tablet计算,从而确定分桶数量
- 最佳实践
- 数据倾斜:如果业务场景中单独采用倾斜度大的列做分桶,很大程度会导致访问数据倾斜,那么建议采用多列组合的方式进行数据分桶。
- 高并发:分区和分桶应该尽量覆盖查询语句所带的条件,这样可以有效减少扫描数据,提高并发。
- 高吞吐:尽量把数据打散,让集群以更高的并发扫描数据,完成相应计算。
- 元数据管理:Tablet 过多会增加 FE/BE 的元数据管理和调度的资源消耗。
表达式分区(推荐)
时间函数表达式分区
时间函数表达式分区
1
2
3
4
5PARTITION BY expression
expression ::=
{ date_trunc ( <time_unit> , <partition_column> ) |
time_slice ( <partition_column> , INTERVAL <N> <time_unit> [ , boundary ] ) }参数 是否必填 说明 expression是 目前仅支持 date_trunc 和 time_slice 函数。并且如果您使用 time_slice函数,则可以不传入参数boundary,因为在该场景中该参数默认且仅支持为floor,不支持为ceil。time_unit是 分区粒度,目前仅支持为 hour、day、month或year,暂时不支持为week。如果分区粒度为hour,则仅支持分区列为 DATETIME 类型,不支持为 DATE 类型。partition_column是 分区列。 仅支持为日期类型(DATE 或 DATETIME),不支持为其它类型。如果使用 date_trunc函数,则分区列支持为 DATE 或 DATETIME 类型。如果使用time_slice函数,则分区列仅支持为 DATETIME 类型。分区列的值支持为NULL。如果分区列是 DATE 类型,则范围支持为 [0000-01-01 ~ 9999-12-31]。如果分区列是 DATETIME 类型,则范围支持为 [0000-01-01 01:01:01 ~ 9999-12-31 23:59:59]。目前仅支持指定一个分区列,不支持指定多个分区列。CREATE TABLE site_access1 ( event_day DATETIME NOT NULL, site_id INT DEFAULT '10', city_code VARCHAR(100), user_name VARCHAR(32) DEFAULT '', pv BIGINT DEFAULT '0' ) DUPLICATE KEY(event_day, site_id, city_code, user_name) PARTITION BY date_trunc('day', event_day) DISTRIBUTED BY HASH(event_day, site_id); -- 分区生命周期管理,即仅保留最近一段时间的分区,删除历史分区,可以使用partition_live_number设置只保留最近多少数量的分区1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
* 在导入的过程中 StarRocks 根据导入数据已经自动创建了一些分区,但是由于某些原因导入作业最终失败,则在当前版本中,已经自动创建的分区并不会由于导入失败而自动删除。
* StarRocks 自动创建分区数量上限默认为 4096,由 FE 配置参数 `max_automatic_partition_number` 决定。该参数可以防止您由于误操作而创建大量分区。
* 分区命名规则:如果存在多个分区列,则不同分区列的值以下划线(_)连接。例如:存在有两个分区列 `dt` 和 `city`,均为字符串类型,导入一条数据 `2022-04-01`, `beijing`,则自动创建的分区名称为 `p20220401_beijing`。
##### 列表达式分区
* 语法
````sqlite
PARTITION BY expression
expression ::=
( <partition_columns> )
partition_columns ::=
<column>, [ <column> [,...] ]参数 是否必填 参数 partition_columns是 分区列。 支持为字符串(不支持 BINARY)、日期、整数和布尔值。不支持分区列的值为 NULL。导入后自动创建的一个分区中只能包含各分区列的一个值,如果需要包含各分区列的多值,请使用 List 分区。partition_live_number否 保留多少数量的分区。比较这些分区包含的值,定期删除值小的分区,保留值大的。后台会定时调度任务来管理分区数量,调度间隔可以通过 FE 动态参数 dynamic_partition_check_interval_seconds配置,默认为 600 秒,即 10 分钟。 说明 如果分区列里是字符串类型的值,则比较分区名称的字典序,定期保留排在前面的分区,删除排在后面的分区。CREATE TABLE t_recharge_detail1 ( id bigint, user_id bigint, recharge_money decimal(32,2), city varchar(20) not null, dt varchar(20) not null ) DUPLICATE KEY(id) PARTITION BY (dt,city) DISTRIBUTED BY HASH(`id`);1
2
3
4
5
6
7
8
9
10
11
12
* ````sqlite
-- 查看分区
SHOW PARTITIONS FROM t_recharge_detail1;
-- 时间表达式分区导入数据
INSERT OVERWRITE site_access1 PARTITION(event_day='2022-06-08 20:12:04')
SELECT * FROM site_access2 PARTITION(p20220608);
-- 列表达式分区导入数据
INSERT OVERWRITE t_recharge_detail1 PARTITION(dt='2022-04-02',city='texas')
SELECT * FROM t_recharge_detail2 PARTITION(p20220402_texas);
List分区
适用于一个分区中需要包含分区列的多个值的场景
1
2
3
4
5
6
7
8
9
10
11
12
13CREATE TABLE t_recharge_detail2 (
id bigint,
user_id bigint,
recharge_money decimal(32,2),
city varchar(20) not null,
dt varchar(20) not null
)
DUPLICATE KEY(id)
PARTITION BY LIST (city) (
PARTITION pCalifornia VALUES IN ("Los Angeles","San Francisco","San Diego"), -- 这些城市同属一个州
PARTITION pTexas VALUES IN ("Houston","Dallas","Austin")
)
DISTRIBUTED BY HASH(`id`);
动态分区
动态分区开启后,按需为新数据动态地创建分区。同时SR会自动删除过期分区,从而保证数据地时效性
CREATE TABLE site_access( event_day DATE, site_id INT DEFAULT '10', city_code VARCHAR(100), user_name VARCHAR(32) DEFAULT '', pv BIGINT DEFAULT '0' ) DUPLICATE KEY(event_day, site_id, city_code, user_name) PARTITION BY RANGE(event_day)( PARTITION p20200321 VALUES LESS THAN ("2020-03-22"), PARTITION p20200322 VALUES LESS THAN ("2020-03-23"), PARTITION p20200323 VALUES LESS THAN ("2020-03-24"), PARTITION p20200324 VALUES LESS THAN ("2020-03-25") ) DISTRIBUTED BY HASH(event_day, site_id) PROPERTIES( "dynamic_partition.enable" = "true", "dynamic_partition.time_unit" = "DAY", "dynamic_partition.start" = "-3", "dynamic_partition.end" = "3", "dynamic_partition.prefix" = "p", "dynamic_partition.history_partition_num" = "0" );1
2
3
4
5
6
7
8
9
10
#### 临时分区
* 可以在一张已经定义分区规则的分区表上,创建临时分区,并为这些临时分区设定单独的数据分布策略
* ````sqlite
ALTER TABLE <table_name>
ADD TEMPORARY PARTITION <temporary_partition_name> VALUES [("value1"), {MAXVALUE|("value2")})]
[(partition_desc)]
[DISTRIBUTED BY HASH(<bucket_key>)];
索引
- SR自动创建的索引,称为内置索引,包括前缀索引,Ordinal索引,ZoneMap索引
- Ordinal索引:分块存储,每个 Data Page 大小一般为 64*1024 个字节(data_page_size = 64 * 1024)。每一个列 Date Page 会对应生成一条 Ordinal 索引项,记录 Data Page 的起始行号等信息。这样 Ordinal 索引提供了通过行号来查找列 Data Page 数据页的物理地址。其他索引查找数据时,最终都要通过 Ordinal 索引查找列 Data Page 的位置。
- ZoneMap索引:ZoneMap 索引存储了每块数据统计信息,统计信息包括 Min 最大值、Max 最小值、HasNull 空值、HasNotNull 不全为空的信息。在查询时,StarRocks 可以根据这些统计信息,快速判断这些数据块是否可以过滤掉,从而减少扫描数据量,提升查询速度。
- 在实现上,“每块”数据可以是一个 Segment,也可以是一个列的一个 Data Page,相应的 ZoneMap 索引有两种:一种是存每个 Segment 的统计信息,另一种是存每个 Data Page 的统计信息
- SR用户手动创建索引,包括Bitmap索引和Bloom filter索引
前缀索引和排序键
- 建表时会指定一个或多个列构成排序键(Sort Key)。表中的数据行会根据排序键进行排序后再落入磁盘存储。在数据写入过程中,会自动生成前缀索引。数据按照指定的排序键后,每写入1024行数据构成一个逻辑数据块(Data Bolck),在前缀索引表中存储一个索引项,内容为改逻辑数据块中第一行数据的排序列组成的前缀。通过这样两层的排序结构,利用二分查找快速跳过不符合条件的数据。
- 注意事项:
- 前缀索引最大长度为36字节,超过部分会被截断,前缀字段的数量不超过三个
- 前缀字段中 char,varchar,string 类型的列只能出现一次,并且出现在末尾
- 合理选择排序键
- 选择经常作为查询过滤条件的列为排序列
- 如果多个排序列作为过滤条件的频率差不多,则可以衡量各排序列的基数特点(即数据的离散度)
- 选择基数高的列可以过滤更多的数据,选择基数低的列则存储压缩率会高很多。
- 排序列的数据类型支持数值(除 DOUBLE、FLOAT)、字符串和日期类型。
Bitmap索引
bitmap(位图索引),bitmap为一个bit数组,一个bit取值有两种:0或1。每个bit对应数据表中的一行,并根据改行的取值情况来决定bit的取值是0还是1。一般适用于高基数列或者高基数列的组合
优势:
- bitmap所占存储空间小
- 支持为多列创建bitmap索引,提高多列的查询效率
使用说明:
- 适用于等值条件(
=)查询或IN的范围查询的列 - 主键表和明细表中所有都可以创建bitmap索引;聚合表和更新表中,只有维度列(即 Key 列)支持创建 bitmap 索引。
- 以下类型的列支持创建bitmap索引:
- 日期类型:DATE、DATETIME。
- 数值类型:TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DECIMAL 和 BOOLEAN。
- 字符串类型:CHAR、STRING 和 VARCHAR。
- 其他类型:HLL。
- 适用于等值条件(
案列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25-- 建表时创建索引
CREATE TABLE d0.table_hash
(
k1 TINYINT,
k2 DECIMAL(10, 2) DEFAULT "10.5",
v1 CHAR(10) REPLACE,
v2 INT SUM,
INDEX index_name (column_name) [USING BITMAP] [COMMENT '']
)
ENGINE = olap
AGGREGATE KEY(k1, k2)
DISTRIBUTED BY HASH(k1)
PROPERTIES ("storage_type" = "column");
-- 建表后创建
CREATE INDEX index_name ON table_name (column_name) [USING BITMAP] [COMMENT ''];
-- 创建 Bitmap 索引为异步过程,查看索引创建进度
SHOW ALTER TABLE COLUMN [FROM db_name];
-- 查看索引
SHOW { INDEX[ES] | KEY[S] } FROM [db_name.]table_name [FROM db_name];
-- 删除索引
DROP INDEX index_name ON [db_name.]table_name;
Bloom filter索引
Bloom filter 索引可以快速判断表的数据文件中是否可能包含要查询的数据,如果不包含就跳过,从而减少扫描的数据量。Bloom filter 索引空间效率高,适用于基数较高的列,如 ID 列。前缀索引对字段长度有限制。超出限制时就可以考虑Bloom filter索引
索引原理:
- Bloom filter索引判断一个数据文件中不存在目标数据,那SR会跳过该文件,从而提高查询效率
- 如果Bloom filter索引判断一个数据文件中可能存在数据目标,那SR会读取该文件确认目标数据是否存在。Bloom filter索引存在一定的误判率,即假阳性概率(False Positive Probability)
使用说明基本和bitmap索引一致
案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18-- 创建索引
CREATE TABLE table1
(
k1 BIGINT,
k2 LARGEINT,
v1 VARCHAR(2048) REPLACE,
v2 SMALLINT DEFAULT "10"
)
ENGINE = olap
PRIMARY KEY(k1, k2)
DISTRIBUTED BY HASH (k1, k2)
PROPERTIES("bloom_filter_columns" = "k1,k2");
-- 查看索引
SHOW CREATE TABLE table1;
-- 修改索引
ALTER TABLE table1 SET ("bloom_filter_columns" = "k1,k2,v1");
数据压缩
- SR支持对表和索引数据进行压缩(compression)。数据压缩不仅有助于节省存储空间,还可以提高 I/O 密集型任务的性能。请注意,压缩和解压缩数据需要额外的 CPU 资源。
- SR支持的压缩算法的压缩率排名:zlib > Zstandard > LZ4 > Snappy
- 如果您对存储空间占用没有特殊需求,建议您使用 LZ4 或 Zstandard 算法。SR默认使用LZ4
导入数据
更多的案例详情直接看官方文档,这里列举几个我常用的
导入概览
- 有多种导入方案,详情
- 导入数据需要Insert权限,通过GRANT给用户赋权
- 访问协议:
- StarRocks 支持通过以下两种访问协议来提交导入作业:MySQL 和 HTTP。当前只有 Stream Load 支持 HTTP 协议,其余导入方式均支持 MySQL 协议。
- 标签机制
- StarRocks 通过导入作业实现数据导入。每个导入作业都有一个标签 (Label),由用户指定或系统自动生成,用于标识该导入作业。每个标签在一个数据库内都是唯一的,仅可用于一个成功的导入作业。一个导入作业成功后,其标签不可再用于提交其他导入作业。只有失败的导入作业的标签,才可再用于提交其他导入作业。
- 数据类型
- 个别的类型可能存在问题,详情可看SR支持的数据类型
- 导入模式
- 同步导入
- 支持同步倒入的方式有Stream Load和INSERT
- 异步导入
- 异步导入是指您创建导入作业以后,StarRocks 直接返回作业创建结果。
- 导入数据流程:参考连接
- 同步导入
从本地文件系统导入
从HDFS导入
- SR支持通过以下方式从HDFS导入数据
使用INSERT+
FILES()进行同步导入1
2
3
4
5
6
7
8
9
10
11
12
13CREATE TABLE tmp.xinjiang AS
SELECT * FROM FILES
(
"path" = "hdfs://192.168.0.156:8020/warehouse/tablespace/external/hive/temp.db/xinjiang/*",
"format" = "orc",
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
SELECT * FROM information_schema.loads ORDER BY JOB_ID DESC;
SELECT * FROM information_schema.loads where label='insert_e0876288-4353-11ef-9ab8-000c291d2710';使用Broker Load进行异步导入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27案例:
/*Hive2SR同步示例*/
/*1、每次同步需换label*/
LOAD LABEL dwd.dwd_policy_etp_project_library_enterprise_ref_df2
(/*2、如下填写Hive对应的hdfs地址,需使用外部表,建表时需要注意,管理表存在权限问题*/
DATA INFILE("hdfs://192.168.0.156:8020/warehouse/tablespace/external/hive/dwd.db/dwd_policy_etp_project_library_enterprise_ref_wf/*")/*确认目前active的hdfs路径*/
INTO TABLE dwd_policy_etp_project_library_enterprise_ref_df
COLUMNS TERMINATED BY "|^|"
FORMAT AS "orc"
(eid, project_id, province_code,city_code,area_code,project_name,score,match_items_ids)/*填写SR表字段顺序映射到hive对应hive的字段名称*/
/*set可以设置sr字段名和hive字段的映射*/
set(
eid=eid,
project_id=project_id,
province_code=province_code,
city_code=city_code,
area_code=area_code,
project_name=project_name,
score=score,
match_item_ids=match_items_ids
)
)
WITH BROKER 'hdfs_broker';
/*查看同步状态*/
use dwd;
show load where label = 'dwd_policy_etp_project_library_enterprise_ref_df2';使用Pipe进行持续的异步导入
INSERT+FILES的优势
FILES()会根据给定的数据路径等参数读取数据,并自动根据数据文件的格式、列信息等推断出表结构,最终以数据行的形式返回文件中的数据。使用方法:
- 使用SELECT语句直接从HDFS查询数据
- 通过CREATE TABLE AS SELECT 语句实现自动建表和导入语句
- 手动建表,然后通过INSERT导入数据
案例
-- 使用SELECT语句直接从HDFS查询数据 SELECT * FROM FILES ( "path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet", "format" = "parquet", "hadoop.security.authentication" = "simple", "username" = "<hdfs_username>", "password" = "<hdfs_password>" ) LIMIT 3; -- CTAS自动建表并导入数据 CREATE TABLE user_behavior_inferred AS SELECT * FROM FILES ( "path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet", "format" = "parquet", "hadoop.security.authentication" = "simple", "username" = "<hdfs_username>", "password" = "<hdfs_password>" ); -- 手动建表并通过INSERT导入数据 CREATE TABLE user_behavior_declared ( UserID int(11), ItemID int(11), CategoryID int(11), BehaviorType varchar(65533), Timestamp varbinary ) ENGINE = OLAP DUPLICATE KEY(UserID) DISTRIBUTED BY HASH(UserID); -- 导入数据 INSERT INTO user_behavior_declared SELECT * FROM FILES ( "path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet", "format" = "parquet", "hadoop.security.authentication" = "simple", "username" = "<hdfs_username>", "password" = "<hdfs_password>" ); -- 查看导入进度 SELECT * FROM information_schema.loads ORDER BY JOB_ID DESC;-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
### 通过导入实现数据变更
* StarRocks 的[主键表](https://docs.starrocks.io/zh/docs/table_design/table_types/primary_key_table/)支持通过 [Stream Load](https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/data-manipulation/STREAM_LOAD/)、[Broker Load](https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/data-manipulation/BROKER_LOAD/) 或 [Routine Load](https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/data-manipulation/CREATE_ROUTINE_LOAD/) 导入作业,对 StarRocks 表进行数据变更,包括插入、更新和删除数据。不支持通过 [Spark Load](https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/data-manipulation/SPARK_LOAD/) 导入作业或 [INSERT](https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/data-manipulation/INSERT/) 语句对 StarRocks 表进行数据变更。
## 数据湖
* [](https://imgse.com/i/pF78qOJ)
* StarRocks 不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据。用户可以通过 StarRocks 提供的 External Catalog,轻松查询存储在 Apache Hive、Apache Iceberg、Apache Hudi、Delta Lake 等数据湖上的数据,无需进行数据迁移。支持的存储系统包括 HDFS、S3、OSS,支持的文件格式包括 Parquet、ORC、CSV。
* 如上图所示,在数据湖分析场景中,StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护。使用数据湖的优势在于可以使用开放的存储格式和灵活多变的 schema 定义方式,可以让 BI/AI/Adhoc/报表等业务有统一的 single source of truth。而 StarRocks 作为数据湖的计算引擎,可以充分发挥向量化引擎和 CBO 的优势,大大提升了数据湖分析的性能。
* SR湖仓一体方案重点在于:
- 规范的Catalog及元数据服务集成
- StarRocks 提供两种类型的 Catalog:Internal Catalog 和 External Catalog。Internal Catalog 用于管理 StarRocks 数据库中存储的数据的元数据。External Catalog 用于连接存储在 Hive、Iceberg、Hudi、Delta Lake 等各种外部数据源中的数据。
- 弹性可扩展的计算节点
- 在存算分离架构下,存储和计算的分离降低了扩展的复杂度。StarRocks 计算节点仅存储本地缓存,方便您根据负载情况灵活地添加或移除计算节点。
- 灵活的缓存机制
- 您可以根据实际情况选择打开或者关闭本地缓存。在计算节点因为负载变化过快而频繁启动和关闭、或者是查询大多集中在近期数据等场景下,数据缓存意义不大,可以无需开启缓存。
### Catalog
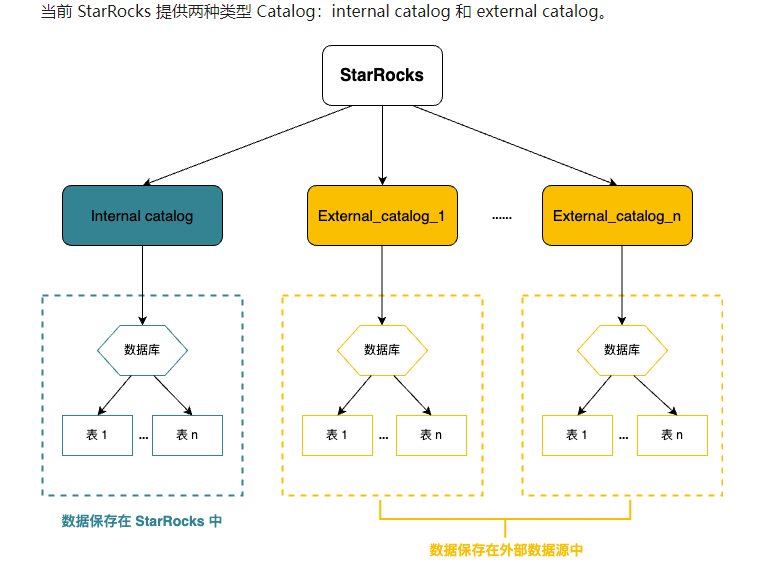
* SR自2.3版本开始支持Catalog(数据目录)功能,实现在一套系统内同时维护内外部数据,方便用户轻松访问并查询存储在各类外部源的数据。
* **内部数据**指是保存在SR中的数据。
* **外部数据**是指保存在外部数据源中的数据。(如hive,iceberg,jdbc)
* [](https://imgse.com/i/pF7YJzT)
- **Internal catalog**: 内部数据目录,用于管理 StarRocks 所有内部数据。例如,执行 CREATE DATABASE 和 CREATE TABLE 语句创建的数据库和数据表都由 internal catalog 管理。 每个 StarRocks 集群都有且只有一个 internal catalog 名为 [default_catalog](https://docs.starrocks.io/zh/docs/data_source/catalog/default_catalog/)。
- **External catalog**: 外部数据目录,用于连接外部 metastore。在 StarRocks 中,您可以通过 external catalog 直接查询外部数据,无需进行数据导入或迁移。当前支持创建以下类型的 external catalog:
- hive
- ````sqlite
-- 案例
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083"
);
-- HA模式
CREATE EXTERNAL CATALOG `hive_metastore_catalog`
PROPERTIES ("hive.metastore.uris" = "thrift://x.x.x.xxx:9083,thrift://x.x.x.xxx:9083",
"metastore_cache_refresh_interval_sec" = "30",
"type" = "hive",
"enable_profile" = "true",
"enable_metastore_cache" = "true"
)
-- 查看所有的catalog
SHOW CATALOGS;
iceberg
hudi
delta lake
jdbc
Elasticsearch catalog:用于查询 Elasticsearch 中的数据。该特性自 3.1 版本起支持。
Paimon catalog:用于查询 Paimon 中的数据。该特性自 3.1 版本起支持。
Unified catalog:把 Hive、Iceberg、Hudi 和 Delta Lake 作为一个融合的数据源,从中查询数据。该特性自 3.2 版本起支持。
在使用external catalog查询数据时,SR会用到外部数据源的两个组件:
- 元数据服务:用于将元数据暴露出来供SR的FE进行查询规划。
- 存储系统:用于存储数据。数据文件以不同的格式存储在分布式文件系统或对象存储系统中。当FE将生成的查询计划分发给各个BE后,各个BE会并行扫描存储系统中的目标数据,并执行计算返回查询结果。
外部表
- StarRocks 支持以外部表 (External Table) 的形式,接入其他数据源。外部表指的是保存在其他数据源中的数据表,而 StartRocks 只保存表对应的元数据,并直接向外部表所在数据源发起查询。目前 StarRocks 已支持的第三方数据源包括 MySQL、StarRocks、Elasticsearch、Apache Hive™、Apache Iceberg 和 Apache Hudi。对于 StarRocks 数据源,现阶段只支持 Insert 写入,不支持读取,对于其他数据源,现阶段只支持读取,还不支持写入。
- 推荐使用JDBC catalog,Hive catalog等
文件外部表
文件外部表 (File External Table) 是一种特殊的外部表。您可以通过文件外部表直接查询外部存储系统上的 Parquet 和 ORC 格式的数据文件,无需导入数据。同时,文件外部表也不依赖任何 Metastore。StarRocks 当前支持的外部存储系统包括 HDFS、Amazon S3 及其他兼容 S3 协议的对象存储、阿里云对象存储 OSS 和腾讯云对象存储 COS。
1
2
3
4
5
6
7
8
9
10
11
12USE db_example;
CREATE EXTERNAL TABLE t0
(
name string,
id int
)
ENGINE=file
PROPERTIES
(
"path"="hdfs://x.x.x.x:8020/user/hive/warehouse/person_parq/",
"format"="parquet"
);
Data Cache
在数据湖分析场景中,SR作为OLAP查询引擎需要扫描HDFS或者其他的外部存储系统,查询实际读取的文件数量越多,I/O开销也越大。为提高查询外部存储系统数据的性能,Data Cache功能可以将外部存储系统的原始数据按照一定策略切分成多个block后,缓存至Starrocks本地的BE节点,避免重复的远端数据拉取开销,实现热点数据查询分析性能的进一步提升。
StarRocks 以 BE 节点的内存和磁盘作为缓存的存储介质,支持全内存缓存或者内存+磁盘的两级缓存。
缓存淘汰机制(LRU)策略来缓存和淘汰数据
- 优先从内存读取数据,内存中没有则再从磁盘上读取。从磁盘上读取的数据,会尝试加载到内存中
- 从内存中淘汰的数据,会尝试写入磁盘;从磁盘上淘汰的数据,会被废弃
常见配置
# 开启 Data Cache。 datacache_enable = true # 设置磁盘路径,假设 BE 机器有两块磁盘。 datacache_disk_path = /home/disk1/sr/dla_cache_data/;/home/disk2/sr/dla_cache_data/ # 设置内存缓存数据量的上限为 2 GB。 datacache_mem_size = 2147483648 # 设置单个磁盘缓存数据量的上限为 1.2 TB。 datacache_disk_size = 12884901888001
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
* Data Cache命中情况可以查看query profile,通过以下三次参数评判cache的命中情况:
- `DataCacheReadBytes`:从内存和磁盘中读取的数据量。
- `DataCacheWriteBytes`:从外部存储系统加载到内存和磁盘的数据量。
- `BytesRead`:总共读取的数据量,包括从内存、磁盘以及外部存储读取的数据量。
#### Data Cache预热
* Data Cache预热是主动填充cache的过程,提前将想要查询的数据放到cache中,是基于Data Cache的扩展。
* 适用场景
- 缓存的磁盘容量大于待预热的数据量
- 缓存盘的数据访问空间比较稳定。
````sqlite
CACHE SELECT <column_name> [, ...]
FROM [<catalog_name>.][<db_name>.]<table_name> [WHERE <boolean_expression>]
[PROPERTIES("verbose"="true")]
CACHE SELECT 可以和 SUBMIT TASK 结合(v3.3后的版本),实现周期性的预热。
查询加速
CBO统计信息
- StarRocks CBO 优化器(Cost-based Optimizer)(基于成本的优化器)
- CBO 优化器是查询优化的关键。一条 SQL 查询到达 StarRocks 后,会解析为一条逻辑执行计划,CBO 优化器对逻辑计划进行改写和转换,生成多个物理执行计划。通过估算计划中每个算子的执行代价(CPU、内存、网络、I/O 等资源消耗),选择代价最低的一条查询路径作为最终的物理查询计划。
- 基于多种统计信息进行代价估算,能够在数万级别的执行计划中,选择代价最低的执行计划,提升复杂查询的效率和性能。
- SR会采集多种统计信息,为查询优化提供代价估算的参考。详细信息
同步物化视图
同步物化视图下,所有对于基表的数据变更都会自动同步更新到物化视图中。您无需手动调用刷新命令,即可实现自动同步刷新物化视图。同步物化视图的管理成本和更新成本都比较低,适合实时场景下单表聚合查询的透明加速。
- 目前, StarRocks 存算分离集群暂不支持同步物化视图。
下表从支持的特性角度比较了 StarRocks 2.5、2.4 中的异步物化视图以及同步物化视图(Rollup):
单表聚合 多表关联 查询改写 刷新策略 基表 异步物化视图 是 是 是 异步刷新手动刷新 支持多表构建。基表可以来自:Default CatalogExternal Catalog(v2.5)已有异步物化视图(v2.5)已有视图(v3.1) 同步物化视图(Rollup) 仅部分聚合函数 否 是 导入同步刷新 仅支持基于 Default Catalog 的单表构建 查询改写是指在对已构建了物化视图的基表进行查询时,系统自动判断是否可以复用物化视图中的预计算结果处理查询。如果可以复用,系统会直接从相关的物化视图读取预计算结果,以避免重复计算消耗系统资源和时间。
-- 创建同步物化视图 CREATE MATERIALIZED VIEW store_amt AS SELECT store_id, SUM(sale_amt) FROM sales_records GROUP BY store_id; -- 查看同步物化视图构建状态 -- 创建同步物化视图是一个异步的操作。CREATE MATERIALIZED VIEW 命令执行成功即代表创建同步物化视图的任务提交成功。您可以通过 SHOW ALTER MATERIALIZED VIEW 命令查看当前数据库中同步物化视图的构建状态。 SHOW ALTER MATERIALIZED VIEW -- 查看同步物化视图的表结构 DESC sales_records ALL -- 删除正在创建的同步物化视图 -- 首先需要通过 查看同步物化视图构建状态 获取该同步物化视图的任务 ID JobID CANCEL ALTER TABLE ROLLUP FROM sales_records (12090); -- 删除已创建的同步物化视图 DROP MATERIALIZED VIEW store_amt;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
* 最佳实践
````sqlite
-- 以下示例基于一张广告业务相关的明细表 advertiser_view_record,其中记录了点击日期 click_time、广告客户 advertiser、点击渠道 channel 以及点击用户 ID user_id。
CREATE TABLE advertiser_view_record(
click_time DATE,
advertiser VARCHAR(10),
channel VARCHAR(10),
user_id INT
) distributed BY hash(click_time);
-- 该场景需要频繁使用如下语句查询点击广告的 UV。
SELECT advertiser, channel, count(distinct user_id)
FROM advertiser_view_record
GROUP BY advertiser, channel;
-- 如需实现精确去重查询加速,您可以基于该明细表创建一张同步物化视图,并使用 bitmap_union() 函数预先聚合数据。
CREATE MATERIALIZED VIEW advertiser_uv AS
SELECT advertiser, channel, bitmap_union(to_bitmap(user_id))
FROM advertiser_view_record
GROUP BY advertiser, channel;
-- 同步物化视图创建完成后,后续查询语句中的子查询 count(distinct user_id) 会被自动改写为 bitmap_union_count (to_bitmap(user_id)) 以便查询命中物化视图。
异步物化视图
- 相较于同步物化视图,异步物化视图支持多表关联以及更加丰富的聚合算子。异步物化视图可以通过手动调用或定时任务的方式刷新,并且支持刷新部分分区,可以大幅降低刷新成本。除此之外,异步物化视图支持多种查询改写场景,实现自动、透明查询加速。
使用场景
- 加速重复聚合查询
- 假设您的数仓环境中存在大量包含相同聚合函数子查询的查询,占用了大量计算资源,您可以根据该子查询建立异步物化视图,计算并保存该子查询的所有结果。建立成功后,系统将自动改写查询语句,直接查询异步物化视图中的中间结果,从而降低负载,加速查询。
- 周期性多表关联查询
- 假设您需要定期将数据仓库中多张表关联,生成一张新的宽表,您可以为这些表建立异步物化视图,并设定定期刷新规则,从而避免手动调度关联任务。异步物化视图建立成功后,查询将直接基于异步物化视图返回结果,从而避免关联操作带来的延迟。
- 数仓分层
- 假设您的基表中包含大量原始数据,查询需要进行复杂的 ETL 操作,您可以通过对数据建立多层异步物化视图实现数仓分层。如此可以将复杂查询分解为多层简单查询,既可以减少重复计算,又能够帮助维护人员快速定位问题。除此之外,数仓分层还可以将原始数据与统计数据解耦,从而保护敏感性原始数据。
- 湖仓加速
- 查询数据湖可能由于网络延迟和对象存储的吞吐限制而变慢。您可以通过在数据湖之上构建异步物化视图来提升查询性能。此外,StarRocks 可以智能改写查询以使用现有的物化视图,省去了手动修改查询的麻烦。
案例
创建异步物化视图的一些说明
- 创建异步物化视图时必须至少指定分桶和刷新策略其中之一。
- 您可以为异步物化视图设置与其基表不同的分区和分桶策略,但异步物化视图的分区列和分桶列必须在查询语句中。
- 异步物化视图支持分区上卷。例如,基表基于天做分区方式,您可以设置异步物化视图按月做分区。
- 异步物化视图暂不支持使用 List 分区策略,亦不支持基于使用 List 分区的基表创建。
- 创建物化视图的查询语句不支持非确定性函数,其中包括 rand()、random()、uuid() 和 sleep()。
- 异步物化视图支持多种数据类型。有关详细信息,请参阅 CREATE MATERIALIZED VIEW - 支持数据类型。
- 默认情况下,执行 CREATE MATERIALIZED VIEW 语句后,StarRocks 将立即开始刷新任务,这将会占用一定系统资源。如需推迟刷新时间,请添加 REFRESH DEFERRED 参数。
异步物化视图刷新,支持异步刷新(ASYNC)和手动刷新(MANUAL)
- 支持设置刷新最大分区数。当一张异步物化视图拥有较多分区时,单次刷新将耗费较多资源。您可以通过设置该刷新机制来指定单次刷新的最大分区数量,从而将刷新任务进行拆分,保证数据量多的物化视图能够分批、稳定的完成刷新。
- 支持为异步物化视图的分区指定 Time to Live(TTL),从而减少异步物化视图占用的存储空间。
- 支持指定刷新范围,只刷新最新的几个分区,减少刷新开销。
- 支持设置数据变更不会触发对应物化视图自动刷新的基表。
- 支持为刷新任务设置资源组。
嵌套物化视图:即基于异步物化视图构建新的异步物化视图。每个异步物化视图的刷新方式仅影响当前物化视图。建议嵌套不要超过三层
案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36-- 基于查询语句创建异步物化视图
CREATE MATERIALIZED VIEW order_mv
DISTRIBUTED BY HASH(`order_id`)
REFRESH ASYNC START('2022-09-01 10:00:00') EVERY (interval 1 day)
AS SELECT
order_list.order_id,
sum(goods.price) as total
FROM order_list INNER JOIN goods ON goods.item_id1 = order_list.item_id2
GROUP BY order_id;
-- 手动刷新物化视图
-- 异步调用刷新任务。
REFRESH MATERIALIZED VIEW order_mv;
-- 同步调用刷新任务。
REFRESH MATERIALIZED VIEW order_mv WITH SYNC MODE;
-- 强制刷新物化视图
refresh MATERIALIZED VIEW tmp.zt_test force;
-- 修改异步物化视图
-- 启用被禁用的异步物化视图(将物化视图的状态设置为 Active)
ALTER MATERIALIZED VIEW order_mv ACTIVE;
-- 修改异步物化视图名称为 order_total
ALTER MATERIALIZED VIEW order_mv RENAME order_total;
-- 修改异步物化视图的最大刷新间隔为 2 天
ALTER MATERIALIZED VIEW order_mv REFRESH ASYNC EVERY(INTERVAL 2 DAY);
-- 查看异步物化视图
SHOW MATERIALIZED VIEWS;
SHOW MATERIALIZED VIEWS WHERE NAME = "order_mv";
SHOW MATERIALIZED VIEWS WHERE NAME LIKE "order%";
-- 查看异步物化视图创建语句
SHOW CREATE MATERIALIZED VIEW order_mv;
-- 删除异步物化视图
DROP MATERIALIZED VIEW order_mv;
使用物化视图进行数据建模
异步物化视图的能力
- 自动刷新:在数据导入至基表后,物化视图可以自动刷新。您无需在外部维护调度任务。
- 分区刷新:通过有时序属性的报表,可以通过分区刷新实现近实时计算。
- 与视图协同使用:通过协同使用物化视图和逻辑视图,您可以实现多层建模,从而实现中间层的重复使用和数据模型的简化。
- Schema Change:您可以通过简单的 SQL 语句更改计算结果,无需修改复杂的数据流水线。
分层建模
利用物化视图实现分层建模
-- 修改基表。 ALTER TABLE <table_name> ADD COLUMN <column_desc>; -- 原子替换基表。 ALTER TABLE <table1> SWAP WITH <table2>; -- 修改视图定义。 ALTER VIEW <view_name> AS <query>; -- 原子替换物化视图(替换两个物化视图的名字,并不修改其中数据)。 ALTER MATERIALIZED VIEW <mv1> SWAP WITH <mv2>; -- 重新启用物化视图。 ALTER MATERIALIZED VIEW <mv_name> ACTIVE;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
* 分区建模
- 利用SR的分区管理,合理的搭配数据建模,实现高效的数据更新。
- 分区管理可以支持多种业务场景
- **事实表更新**:您可以将事实表分区到细粒度级别,例如按日或按小时。在事实表更新后,物化视图中相应的分区将自动刷新。
- **维度表更新**:通常,维度表中的数据更新将导致所有关联结果的刷新,刷新代价较大。您可以选择忽略某些维度表中的数据更新,以避免刷新整个物化视图,或者您可以指定一个时间范围,从而只有在该时间范围内的分区才能被刷新。
- **外部表的自动刷新**:在类似于 Apache Hive 或 Apache Iceberg 这样的外部数据源中,数据往往以分区的粒度进行变更。StarRocks 的物化视图可以订阅外表分区级别的数据更新,只刷新物化视图的相应分区。
- **TTL**:在为物化视图设置分区策略时,您可以设置要保留的最近分区的数量,从而仅保留最新的数据。其对应的业务场景对数据时效性有较高要求,例如,分析师仅需要查询某个时间窗口内的最新数据,而无需保留所有历史数据。
#### 物化视图查询改写
* 利用物化视图来查询改写并加速查询。(创建物化视图后,类似的查询会利用物化视图预计算的结果,会大幅提升查询速度,降低计算成本)
* 功能特点
- **强数据一致性**:如果基表是 StarRocks 内表,StarRocks 可以保证通过物化视图查询改写获得的结果与直接查询基表的结果一致。
- **Staleness rewrite**:StarRocks 支持 Staleness rewrite,即允许容忍一定程度的数据过期,以应对数据变更频繁的情况。
- **多表 Join**:StarRocks 的异步物化视图支持各种类型的 Join,包括一些复杂的 Join 场景,如 View Delta Join 和 Join 派生改写,可用于加速涉及大宽表的查询场景。
- **聚合改写**:StarRocks 可以改写带有聚合操作的查询,以提高报表性能。
- **嵌套物化视图**:StarRocks 支持基于嵌套物化视图改写复杂查询,扩展了可改写的查询范围。
- **Union 改写**:您可以将 Union 改写特性与物化视图分区的生存时间(TTL)相结合,实现冷热数据的分离,允许您从物化视图查询热数据,从基表查询历史数据。
- **基于视图构建物化视图**:您可以在基于视图建模的情景下加速查询。
- **基于 External Catalog 构建物化视图**:您可以通过该特性加速数据湖中的查询。
- **复杂表达式改写**:支持在表达式中调用函数和算术运算,满足复杂分析和计算需求。
##### join改写
* StarRocks 支持改写具有各种类型 Join 的查询
* StarRocks 异步物化视图的多表聚合查询改写支持所有聚合函数,包括 bitmap_union、hll_union 和 percentile_union 等
##### 聚合改写
* 聚合上卷改写
- StarRocks 支持通过聚合上卷改写查询,即 StarRocks 可以使用通过 GROUP BY a,b 子句创建的异步物化视图改写带有 GROUP BY a 子句的聚合查询
* 聚合下推
- 从 v3.3.0 版本开始,StarRocks 支持物化视图查询改写的聚合下推功能
* count distinct改写
- StarRocks 支持将 COUNT DISTINCT 计算改写为 BITMAP 类型的计算,从而使用物化视图实现高性能、精确的去重。
- ````sqlite
CREATE MATERIALIZED VIEW distinct_mv
DISTRIBUTED BY hash(lo_orderkey)
AS
SELECT lo_orderkey, bitmap_union(to_bitmap(lo_custkey)) AS distinct_customer
FROM lineorder
GROUP BY lo_orderkey;
-- 上面的物化视图可以改写下面的查询
SELECT lo_orderkey, count(distinct lo_custkey)
FROM lineorder
GROUP BY lo_orderkey;
嵌套物化视图改写
- StarRocks 支持使用嵌套物化视图改写查询。
Union改写
谓词Union改写:当物化视图的谓词范围是查询的谓词范围的子集时,可以使用 UNION 操作改写查询。
CREATE MATERIALIZED VIEW agg_mv4 DISTRIBUTED BY hash(lo_orderkey) AS SELECT lo_orderkey, sum(lo_revenue) AS total_revenue, max(lo_discount) AS max_discount FROM lineorder WHERE lo_orderkey < 300000000 GROUP BY lo_orderkey; -- 该物化视图可以改写以下查询 select lo_orderkey, sum(lo_revenue) AS total_revenue, max(lo_discount) AS max_discount FROM lineorder GROUP BY lo_orderkey;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
* 分区Union改写:假设基于分区表创建了一个分区物化视图。当查询扫描的分区范围是物化视图最新分区范围的超集时,查询可被 UNION 改写。
##### 基于视图的物化视图查询改写
- 自 v3.1.0 起,StarRocks 支持基于视图创建物化视图。如果基于视图的查询为 SPJG 类型,StarRocks 将会内联展开查询,然后进行改写。默认情况下,对视图的查询会自动展开为对视图的基表的查询,然后进行透明匹配和改写。
##### 基于External Catalog构建物化视图
* StarRocks 支持基于 Hive Catalog、Hudi Catalog、Iceberg Catalog 和 Paimon Catalog 的外部数据源上构建异步物化视图,并支持透明地改写查询。基于 External Catalog 的物化视图支持大多数查询改写功能
##### 验证查询是否改写
* 可以使用 EXPLAIN 语句查看对应 Query Plan。如果其中 OlapScanNode 项目下的 TABLE 为对应异步物化视图名称,则表示该查询已基于异步物化视图改写。
#### 使用物化视图加速数据湖查询
* StarRocks 提供了开箱即用的数据湖查询功能,非常适用于对湖中的数据进行探查式查询分析。在大多数情况下,[Data Cache](https://docs.starrocks.io/zh/docs/data_source/data_cache/) 可以提供 Block 级文件缓存,避免由远程存储抖动和大量I/O操作引起的性能下降。
然而,当涉及到使用湖中数据构建复杂和高效的报表,或进一步加速这些查询时,您可能仍然会遇到性能挑战。通过使用异步物化视图,您可以为数据湖中的报表和应用实现更高的并发,以及更好的性能。
##### 概述
* 数据湖报表的透明加速
* 实时数据与离线数据关联的增量计算
* 指标层的快速搭建
| | Data Cache | 物化视图 | 本地表 |
| ------------------ | ------------------------------------------------------------ | ---------------------------------------------------------- | ---------------------------------------- |
| **数据导入和更新** | 查询会自动触发数据缓存 | 自动触发刷新任务 | 支持各种导入方法,但需要手动维护导入任务 |
| **数据缓存粒度** | 支持 Block 级数据缓存遵循 LRU 缓存淘汰机制不缓存计算结果 | 存储预计算的查询结果 | 基于表定义存储数据 |
| **查询性能** | Data Cache ≤ 物化视图 = 本地表 | | |
| **查询语句** | 无需修改针对湖数据的查询语句一旦查询命中缓存,就会进行现场计算。 | 无需修改针对湖数据的查询语句利用查询改写重用预先计算的结果 | 需要修改查询语句以查询本地表 |
* 与直接查询数据湖数据或将数据导入到本地表中相比,物化视图有几个独特的优势:
- **本地存储加速**:物化视图可以利用 StarRocks 的本地存储加速优势,如索引、分区分桶和 Colocate Group,从而相较直接从数据湖查询数据具有更好的查询性能。
- **无需维护加载任务**:物化视图通过自动刷新任务透明地更新数据,无需维护导入任务。此外,基于 Hive、Iceberg 和 Paimon Catalog 的物化视图可以检测数据更改并在分区级别执行增量刷新。
- **智能查询改写**:查询可以被透明改写至物化视图,无需修改应用使用的查询语句即可加速查询。
#### 创建分区物化视图
* SR的异步物化视图支持多种分区策略和函数,方便实现
- **增量构建**
在创建分区物化视图时,您可以设置分区刷新任务分批执行,以避免所有分区并行刷新导致过多资源消耗。
- **增量刷新**
您可以将刷新任务设置为基表分区有数据更新时,仅更新物化视图的相应分区。分区级别的刷新可以显著减少刷新整个物化视图所导致的资源浪费。
- **局部物化**
您可以为物化视图分区设置 TTL,从而实现数据的部分物化。
- **透明查询改写**
查询可以仅基于最新的物化视图分区进行透明改写。过期的分区不会参与查询计划,相应查询将在基表上直接执行,从而确保数据的一致性。
- ````sqlite
CREATE MATERIALIZED VIEW <name>
REFRESH ASYNC
PARTITION BY
[
<base_table_column> |
date_trunc(<granularity>, <base_table_column>) |
time_slice(<base_table_column>, <granularity>) |
date_slice(<base_table_column>, <granularity>)
]
AS <query>
使用限制
- 分区物化视图只能在分区基表(通常是事实表)上创建。您需要通过映射基表和物化视图之间的分区关系建立两者之间的协同关系。
语法使用
常见使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46-- 创建语句(CREATE)
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [database.]<mv_name>
[COMMENT ""]
-- distribution_desc
[DISTRIBUTED BY HASH(<bucket_key>[,<bucket_key2> ...]) [BUCKETS <bucket_number>]]
-- refresh_desc
[REFRESH
-- refresh_moment
[IMMEDIATE | DEFERRED]
-- refresh_scheme
[ASYNC | ASYNC [START (<start_time>)] EVERY (INTERVAL <refresh_interval>) | MANUAL]
]
-- partition_expression
[PARTITION BY
{<date_column> | date_trunc(fmt, <date_column>)}
]
-- order_by_expression
[ORDER BY (<sort_key>)]
[PROPERTIES ("key"="value", ...)]
AS
<query_statement>
-- 修改语句(ALTER)
-- 修改物化视图名称
ALTER MATERIALIZED VIEW lo_mv1 RENAME lo_mv1_new_name;
-- 修改物化视图刷新间隔
ALTER MATERIALIZED VIEW lo_mv2 REFRESH ASYNC EVERY(INTERVAL 1 DAY);
-- 修改物化视图属性
-- 修改 mv1 的 query_timeout 为 40000 秒。
ALTER MATERIALIZED VIEW mv1 SET ("session.query_timeout" = "40000");
-- 修改 mv1 的 mv_rewrite_staleness_second 为 600 秒。
ALTER MATERIALIZED VIEW mv1 SET ("mv_rewrite_staleness_second" = "600");
-- 修改物化视图状态为 Active
ALTER MATERIALIZED VIEW order_mv ACTIVE;
-- 原子替换物化视图 order_mv 和 order_mv1
ALTER MATERIALIZED VIEW order_mv SWAP WITH order_mv1;
-- 删除语句(DROP)
DROP MATERIALIZED VIEW [IF EXISTS] [database.]mv_name
-- 展示所有或指定异步物化视图信息(SHOW)
SHOW MATERIALIZED VIEWS
[FROM db_name]
[
WHERE NAME { = "mv_name" | LIKE "mv_name_matcher"}
]
异步物化视图故障排除
检查异步物化视图
-- 检查异步物化视图工作状态 SHOW MATERIALIZED VIEWS like 'dwd_msg_indu_ref_hf' -- 查看异步物化视图的刷新历史 -- task_name 通过异步物化视图的工作状态结果查看 SELECT * FROM information_schema.task_runs WHERE task_name ='mv-242138' -- 监控异步物化视图的资源消耗情况 show PROC -- 验证查询是否被异步物化视图改写 -- 通过explain查看执行计划,检查查询是否可以被异步物化视图重写 EXPLAIN LOGICAL select * from dwd_msg_indu_ref_hf;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
*
##### 诊断并解决故障
* ````sqlite
-- 创建物化视图失败
-- 1.检查是否误用了创建同步物化视图的 SQL 语句。
-- 2.检查是否指定了正确的 Partition By 列。
-- 3.检查您是否具有创建物化视图所需的权限。
-- 物化视图刷新失败
-- 1.检查是否采用了不合适的刷新策略。
-- 2.检查刷新任务是否超出了内存限制。
-- 3.检查刷新任务是否超时。
-- 物化视图不可用
ALTER MATERIALIZED VIEW mv1 ACTIVE;
-- 物化视图刷新任务占用过多资源
-- 1.检查创建的物化视图是否过大
-- 2.检查刷新间隔是否过于频繁
-- 3.检查物化视图是否已分区
-- 物化视图无法改写查询
-- 1.检查物化视图和查询是否匹配
-- 2.检查物化视图的状态是否为 Active
-- 3.检查物化视图是否满足数据一致性要求
-- 4.检查物化视图的查询语句是否缺少输出列
Colocate join
- Colocate Join 功能是分布式系统实现 Join 数据分布的策略之一,能够减少数据多节点分布时 Join 操作引起的数据移动和网络传输,从而提高查询性能。
Lateral join 实现列转行
行列转换功能,Lateral Join 功能能够将每行数据和内部的子查询或者 Table Function 关联。通过 Lateral Join 与 Unnest 功能配合,您可以实现一行转多行的功能。 unnest函数详情。
unnest函数注意事项
- UNNEST 必须与 lateral join 一起使用,但是 lateral join 关键字可以在查询中省略。
- 支持输入多个数组,数组的长度和类型可以不同。
- 多个 array 的元素类型和长度(元素个数)可以不同。对于长度不同的情况,以最长数组的长度为基准,长度小于这个长度的数组使用 NULL 进行元素补充
- 如果输入的数组为 NULL 或 空,则计算时跳过。
- 如果数组中的某个元素为 NULL,该元素对应的位置返回 NULL。
-- 完整 SQL 语句。 SELECT student, score, t.unnest FROM tests CROSS JOIN LATERAL UNNEST(scores) AS t; -- 简化 SQL 语句。您可以使用 Unnest 关键字省略 Lateral Join 关键字。 SELECT student, score, t.unnest FROM tests, UNNEST(scores) AS t; -- 示例一:UNNEST 接收一个参数 -- 创建表 student_score,其中 scores 为 ARRAY 类型的列。 CREATE TABLE student_score ( `id` bigint(20) NULL COMMENT "", `scores` ARRAY<int> NULL COMMENT "" ) DUPLICATE KEY (id) DISTRIBUTED BY HASH(`id`); -- 向表插入数据。 INSERT INTO student_score VALUES (1, [80,85,87]), (2, [77, null, 89]), (3, null), (4, []), (5, [90,92]); --查询表数据。 SELECT * FROM student_score ORDER BY id; +------+--------------+ | id | scores | +------+--------------+ | 1 | [80,85,87] | | 2 | [77,null,89] | | 3 | NULL | | 4 | [] | | 5 | [90,92] | +------+--------------+ -- 将 scores 列中的数组元素展开成多行。 SELECT id, scores, unnest FROM student_score, unnest(scores) AS unnest; +------+--------------+--------+ | id | scores | unnest | +------+--------------+--------+ | 1 | [80,85,87] | 80 | | 1 | [80,85,87] | 85 | | 1 | [80,85,87] | 87 | | 2 | [77,null,89] | 77 | | 2 | [77,null,89] | NULL | | 2 | [77,null,89] | 89 | | 5 | [90,92] | 90 | | 5 | [90,92] | 92 | +------+--------------+--------+ -- 示例二:UNNEST 接收多个参数 -- 创建表。 CREATE TABLE example_table ( id varchar(65533) NULL COMMENT "", type varchar(65533) NULL COMMENT "", scores ARRAY<int> NULL COMMENT "" ) ENGINE=OLAP DUPLICATE KEY(id) COMMENT "OLAP" DISTRIBUTED BY HASH(id) PROPERTIES ( "replication_num" = "3"); -- 向表插入数据。 INSERT INTO example_table VALUES ("1", "typeA;typeB", [80,85,88]), ("2", "typeA;typeB;typeC", [87,90,95]); -- 查询表中数据。 SELECT * FROM example_table; +------+-------------------+------------+ | id | type | scores | +------+-------------------+------------+ | 1 | typeA;typeB | [80,85,88] | | 2 | typeA;typeB;typeC | [87,90,95] | +------+-------------------+------------+ -- 使用 UNNEST 将 type 和 scores 这两列中的元素展开为多行。 SELECT id, unnest.type, unnest.scores FROM example_table, unnest(split(type, ";"), scores) AS unnest(type,scores); +------+-------+--------+ | id | type | scores | +------+-------+--------+ | 1 | typeA | 80 | | 1 | typeB | 85 | | 1 | NULL | 88 | | 2 | typeA | 87 | | 2 | typeB | 90 | | 2 | typeC | 95 | +------+-------+--------+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
* ````sqlite
-- 如果输入的数组为 NULL 或 空,则计算时跳过。
CREATE TABLE lateral_test (
`v1` bigint(20) NULL COMMENT "",
`v2` ARRAY<int> NULL COMMENT ""
)
DUPLICATE KEY(v1)
DISTRIBUTED BY HASH(`v1`)
PROPERTIES (
"replication_num" = "3",
"storage_format" = "DEFAULT"
);
INSERT INTO lateral_test VALUES (1, [1,2]), (2, [1, null, 3]), (3, null);
mysql> select v1, v2, unnest from lateral_test, unnest(v2) as unnest;
+------+------------+--------+
| v1 | v2 | unnest |
+------+------------+--------+
| 1 | [1,2] | 1 |
| 1 | [1,2] | 2 |
| 2 | [1,null,3] | 1 |
| 2 | [1,null,3] | NULL |
| 2 | [1,null,3] | 3 |
+------+------------+--------+
Query Cache
开启 Query Cache 后,每次处理聚合查询时,StarRocks 都会将本地聚合的中间结果缓存于内存中。后续收到相同或类似的聚合查询时,StarRocks 就能够直接从 Query Cache 获取匹配的聚合结果,而无需从磁盘读取数据并进行计算,大大节省查询的时间和资源成本
应用场景
- 查询多为宽表模型下的单表聚合查询或星型模型下简单多表 JOIN 的聚合查询。
- 聚合查询以非 GROUP BY 聚合和低基数 GROUP BY 聚合为主。
- 查询的数据以按时间分区追加的形式导入,并且在不同时间分区上的访问表现出冷热性。
数据去重
使用Bitmap实现精确去重
bitmap就是利用所谓 BitMap 就是用一个 bit 位来标记某个元素对应的 value,而 key 即是这个元素。由于采用bit为单位来存储数据,因此在可以大大的节省存储空间。
- Bitmap 去重能够准确计算一个数据集中不重复元素的数量,相比传统的 Count Distinct,可以节省存储空间、加速计算。例如,给定一个数组 A,其取值范围为 [0, n),可采用 (n+7)/8 的字节长度的 bitmap 对该数组去重。即将所有 bit 初始化为 0,然后以数组 A 中元素的取值作为 bit 的下标,并将 bit 置为 1,那么 bitmap 中 1 的个数即为数组 A 中不同元素 (Count Distinct) 的数量。
Bitmap index 和 Bitmap 去重二者虽然都使用 Bitmap 技术,但引入原因和解决的问题完全不同。前者用于低基数的枚举型列的等值条件过滤,后者则用于计算一组数据行的指标列的不重复元素的个数。
从 StarRocks 2.3 版本开始,所有数据模型表的指标列均支持设置为 BITMAP 类型,但是所有数据模型表的不支持排序键为 BITMAP 类型。
建表时,指定指标列类型为 BITMAP,使用 BITMAP_UNION 函数进行聚合。
StarRocks 的 bitmap 去重是基于 Roaring Bitmap 实现的,roaring bitmap 只能对 TINYINT,SMALLINT,INT 和 BIGINT 类型的数据去重。如想要使用 Roaring Bitmap 对其他类型的数据去重,则需要构建全局字典。
bitmap去重案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44--
CREATE TABLE `page_uv` (
`page_id` INT NOT NULL COMMENT '页面id',
`visit_date` datetime NOT NULL COMMENT '访问时间',
`visit_users` BITMAP BITMAP_UNION NOT NULL COMMENT '访问用户id'
) ENGINE=OLAP
AGGREGATE KEY(`page_id`, `visit_date`)
DISTRIBUTED BY HASH(`page_id`)
PROPERTIES (
"replication_num" = "3",
"storage_format" = "DEFAULT"
);
INSERT INTO page_uv VALUES
(1, '2020-06-23 01:30:30', to_bitmap(13)),
(1, '2020-06-23 01:30:30', to_bitmap(23)),
(1, '2020-06-23 01:30:30', to_bitmap(33)),
(1, '2020-06-23 02:30:30', to_bitmap(13)),
(2, '2020-06-23 01:30:30', to_bitmap(23));
在 page_id = 1, visit_date = '2020-06-23 01:30:30' 数据行,visit_users 字段包含 3 个 bitmap 元素(13,23,33);
在 page_id = 1, visit_date = '2020-06-23 02:30:30' 的数据行,visit_users 字段包含 1 个 bitmap 元素(13);
在 page_id = 2, visit_date = '2020-06-23 01:30:30' 的数据行,visit_users 字段包含 1 个 bitmap 元素(23)。
select page_id, count(distinct visit_users) from page_uv group by page_id;
+-----------+------------------------------+
| page_id | count(DISTINCT `visit_users`) |
+-----------+------------------------------+
| 1 | 3 |
+-----------+------------------------------+
| 2 | 1 |
+-----------+------------------------------+
2 row in set (0.00 sec)
-- bitmap_union(value)使用
-- value支持的类型为bitmap
select page_id, bitmap_count(bitmap_union(user_id))
from table
group by page_id;
-- 等价于下面的sql
select page_id, count(distinct user_id)
from table
group by page_id;目前bitmap类型不支持除整数类型之外的类型,如果想对string等类型作为bitmap的输入,则需要构建全局字典
使用HyperLogLog实现近似去重
- HLL 是一种近似去重算法,在部分对去重精度要求不高的场景下,您可以选择使用 HLL 算法减轻数据去重分析的计算压力。根据数据集大小以及所采用的哈希函数的类型,HLL 算法的误差可控制在 1% 至 10% 左右。
使用 AUTO INCREMENT 列构建全局字典以加速精确去重计算和 Join
- 阶段一: 创建全局字典并构建 STRING 值和 INTEGER 值之间的映射关系。字典中 key 列为 STRING 类型,value 列为 INTEGER 类型且为自增列。每次导入数据时候,系统都会自动为每个 STRING 值生成一个表内全局唯一的 ID,如此就建立了 STRING 值和 INTEGER 值之间的映射关系。
- 阶段二:将订单数据和全局字典的映射关系导入至目标表。
- 阶段三:后续查询分析时基于目标表的 INTEGER 列来计算精确去重或 Join,可以显著提高性能。
- 阶段四:为了进一步优化性能,您还可以在 INTEGER 列上使用 bitmap 函数来进一步加速计算精确去重。
常见问题
- 关于StarRocks的字符串类型的一些问题:
1.SR字符串的单位是字节。varchar(255),表示只能存255字节的数据。
2.但是对于中文字符来说,一个中文字符占了三个字节。所以同样varchar(255)的情况下,mysql会比SR多存很多个中文字符。
3.创建物化视图时,当SR varcha(255)存不下的时候,该条数据会被舍弃。
4.还有一个就是SR的string类型,最大字节数是65533,即varchar(65533)。如果长度超长,用中台同步数据不会丢失,但是该字段为空。
5.自 StarRocks 2.1 版本开始,varchar(M) M的取值范围为 [1, 1048576]。M是字节数
所以后续可能要特别注意中文字符串丢数据或者缺失数据的情况。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!